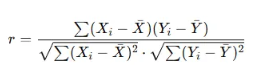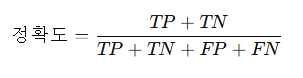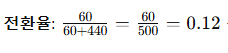3일 일정 및 역할 분배4명이서 진행하는 경우, EDA는 각자 개별적으로 진행한 후, 3일 동안 가설 설정, 예측 모델링, 분석, 보고서 작성 및 발표 준비를 진행하는 최적의 역할 분배안을 정리1. 역할 분배 (4인 기준)역할담당자주요 업무A: 데이터 리더팀원 1데이터 전처리, 피처 엔지니어링B: 모델링 담당팀원 2머신러닝 모델 구축 및 성능 평가C: 인사이트 분석 담당팀원 3예측 결과 분석 및 비즈니스 인사이트 도출D: 보고서 및 발표 담당팀원 4최종 보고서 및 발표 자료 제작 2. 3일 일정 (하루 7시간 기준)Day 1: 가설 설정 및 데이터 전처리(공통) 개별 EDA 결과 공유 (1시간)(A: 데이터 리더) 데이터 전처리 및 피처 엔지니어링 (4시간)(B: 모델링 담당) 예측 모델 기초 설계 및 ..