파이썬을 따로 설치 해도 되지만 아나콘다 배포판을 설치하면 판다스와 넘파이 등 데이터 분석에 필요한 필수 라이브러리들이 자동으로 기본 설치된다. 다운로드 하는것을 추천하며 아래는 가상환경에서 하는것을 기준으로 합니다.
모든게 설치된 base에서 하면 편하기는 하지만 처음 고생하는것을 추천합니다.
그래야 가상환경이 무엇이고 필요한 라이브러리는 어떤것이 있어야된다는걸 더 실감나게 알수 있습니다.







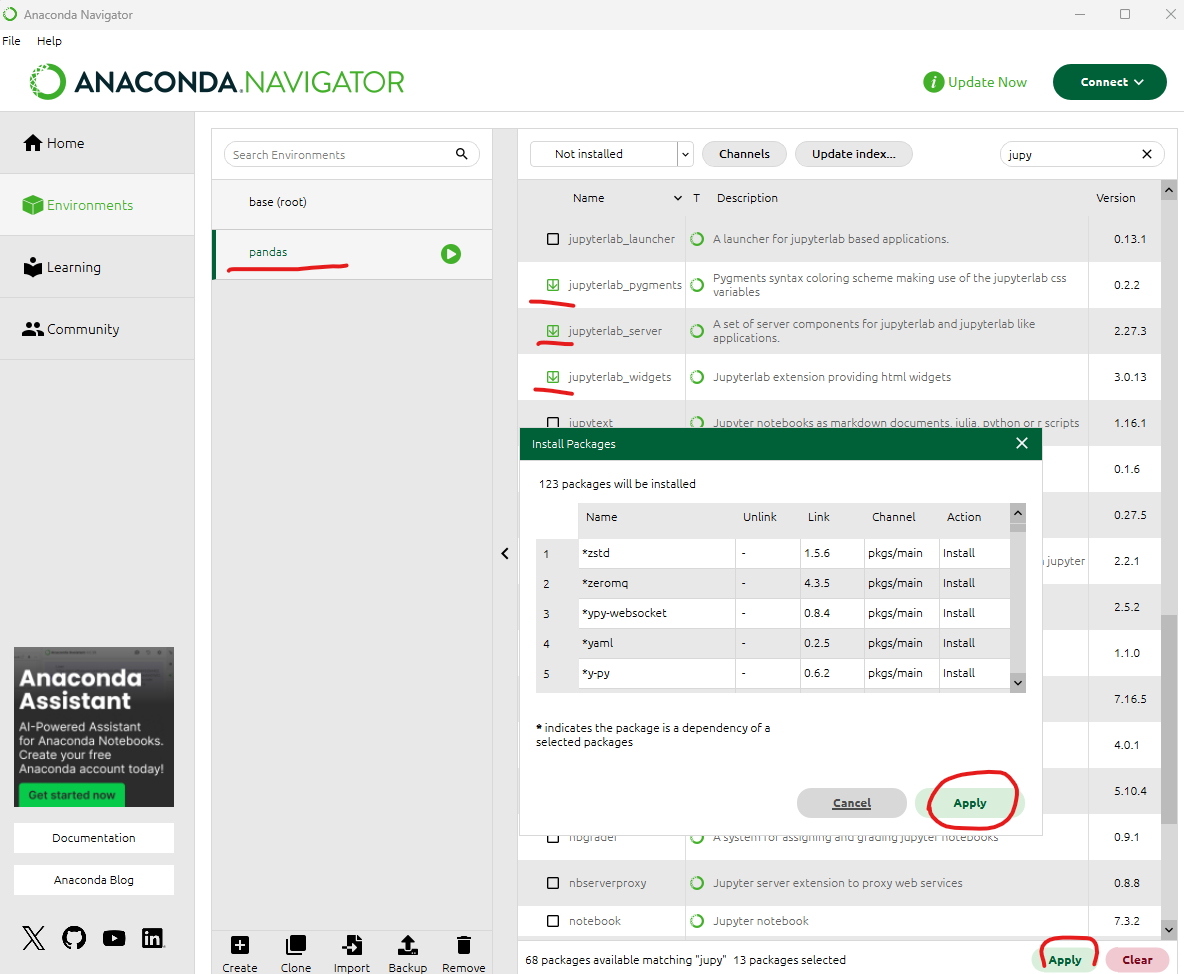


윈도우 검색에서 "Anaconda"를 입력하고 아나콘다 프롬프트(Anaconda Prompt)를 실행하면 도스창이 뜬다.
mkdir pandas로 폴더를 만들고 cd pandas 폴더로 이동한다.
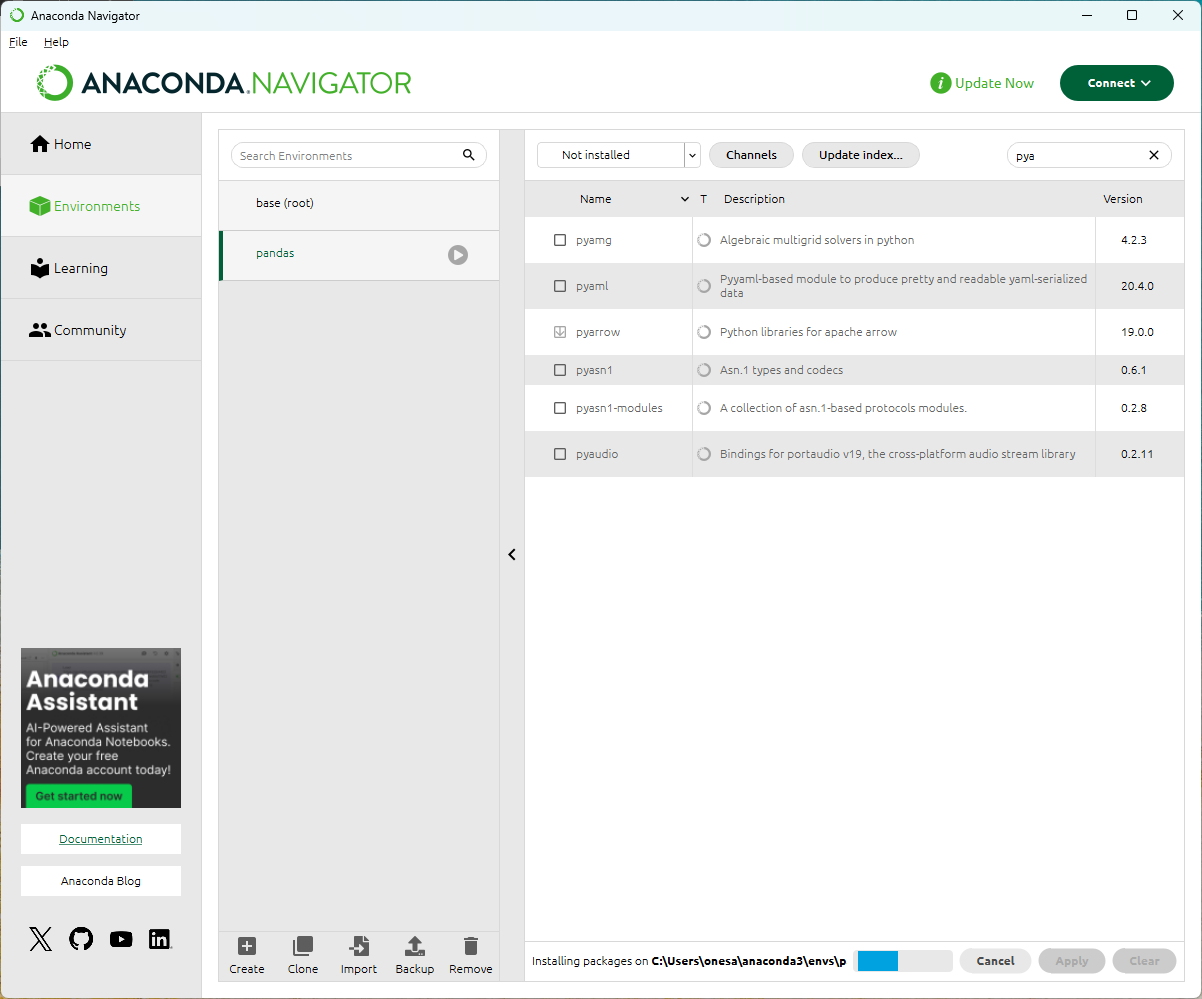
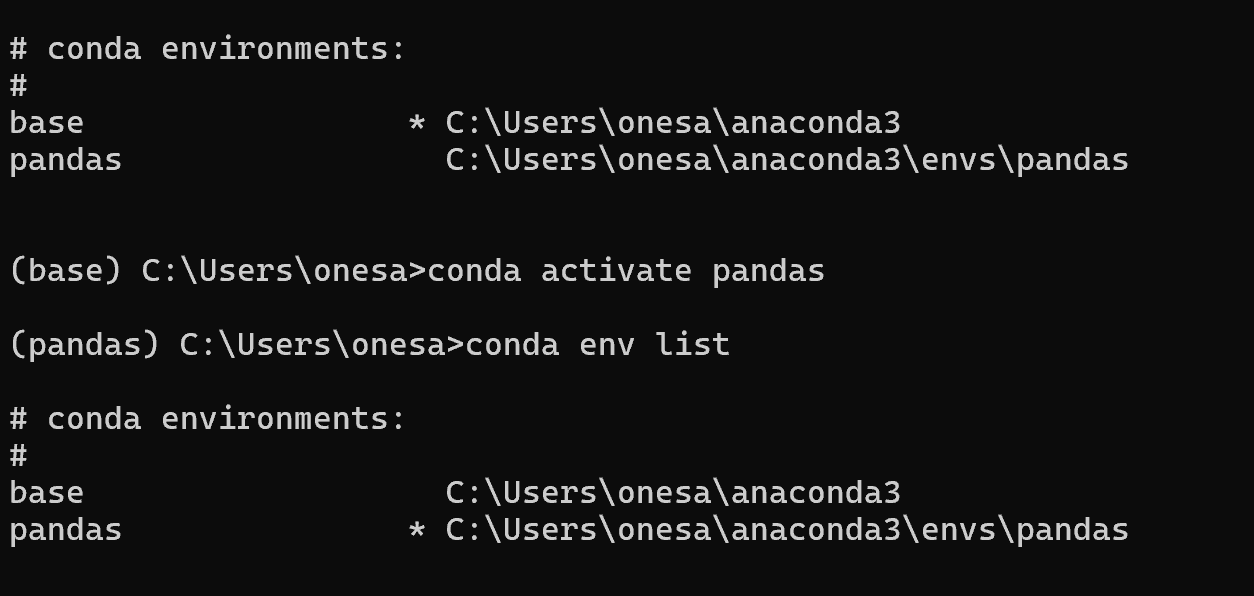
conda env list는 현재 가상환경을 출력한다. 현재 활성화되어 있는 환경에 * 표시가 있다
conda activate pandas 명령을 실행하면 추가한 pandas가상환경을 활성화 한다.
그럼 아래 처럼 앞에 (pandas)부분이 표시되어 현재 활성화된 가상환경을 확인할 수 있다.
파이썬 패키지 관리자(pip)를 통해 ipykernel패키지를 pandas 가상환경에 설치한다.
pip install ipykernel명령을 입력하고 실행 한번만 해주면됨.
아래 명령어를 실행하면 pandas 가상환경을 Jupyter Notebook 환경에서 인식할 수 있도록 추가된다.

여기서 한단계가 빠져서 고생좀 했습니다 ㅜㅜ 가상환경으로 하기때문에 아래 내용이 들어있는 텍스트 파일로 설치를 해야 됩니다.
folium==0.15.1
lxml==5.1.0
matplotlib==3.8.2
numpy==1.26.3
openpyxl==3.1.2
pandas==2.2.0
pillow==10.2.0
pyarrow==15.0.0
scikit-learn==1.4.0
scipy==1.12.0
seaborn==0.13.2
tzdata==2023.4
beautifulsoup4==4.12.2
missingno==0.5.2
이내용이 들어 있는 파일을 아나콘다 프롬프트에서 pip install -r 텍스트파일.txt 아래로 실행하여 설치



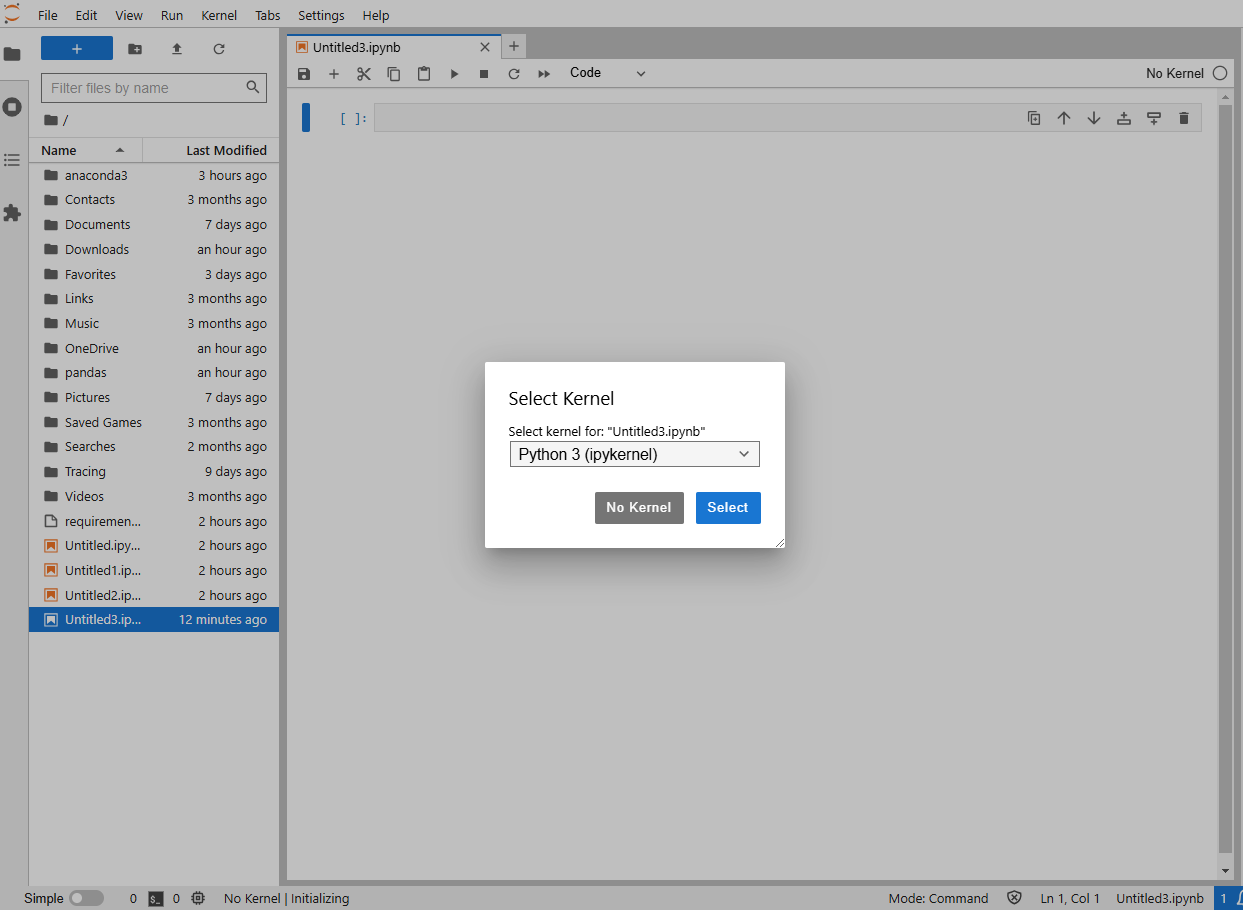

여기서 jupyter lab을 실행중일때는 아나콘다 프롬프트창을 닫으면 안되는거 같습니다. 연결이 끊어졌다고 메시지가 뜨는거 보니. (주의)

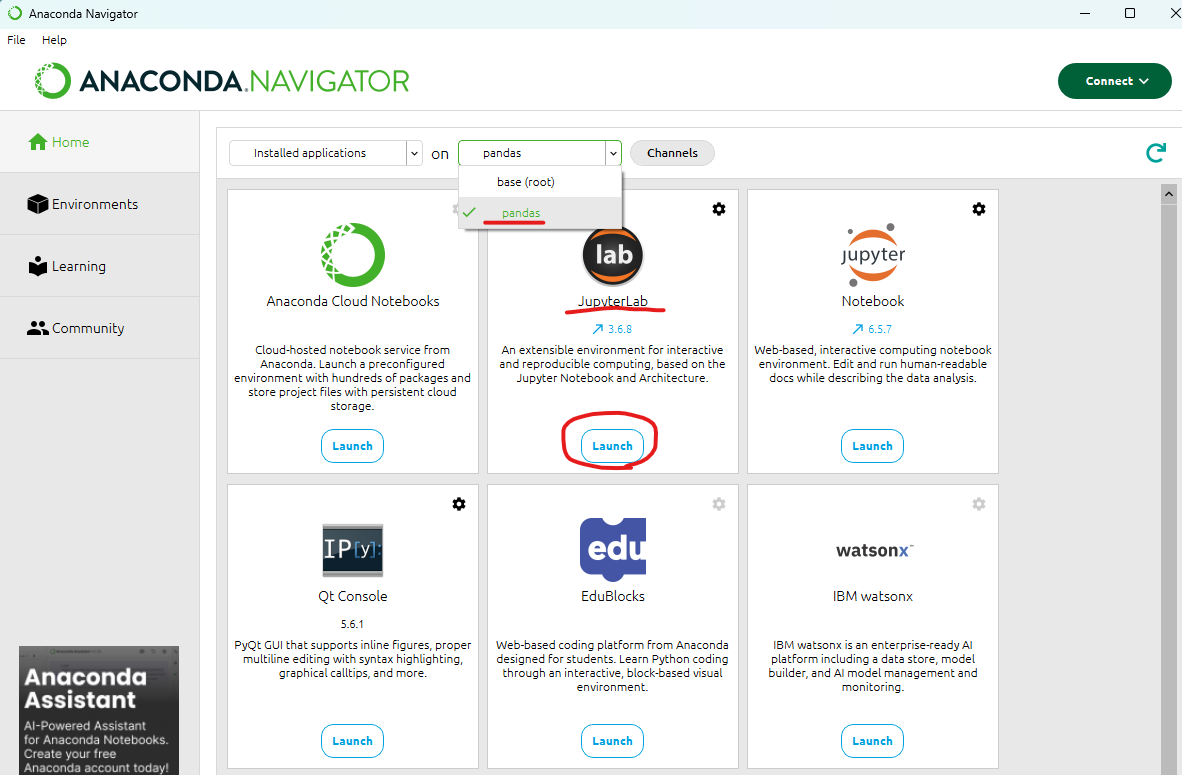
주식관련 데이터가 필요할때 필요한 조치
pip install pykrx 로 이 라이브러리는 해당 시점에 네이버와 KRX 페이지에서 접근하여 주식 관련 데이터를 실시간에 가져옵니다. 실시간 스크래핑 방식이기에 대량의 데이터를 가져오는데는 다소 시간이 소요될 수 있습니다. 한 종목 또는 지수에 대해 20년치 정도의 데이터를 가져오는데 대략 1분 정도가 소요됩니다. 대량의 동일 데이터를 반복해서 사용하고자 하는 경우에는, 따로 저장해 두고 재사용하는 것이 효율적입니다.

'데이터 분석가:Applied Data Analytics > 파이썬' 카테고리의 다른 글
| Git을 사용 파일 복제(clone) 하기 (0) | 2025.03.21 |
|---|---|
| Python(파이썬) 함수 용어 (0) | 2025.02.15 |
| 가상공간(가상 환경, Virtual Environment)의 개념 (1) | 2025.02.06 |
| 파이썬으로 게임만들기 (0) | 2025.02.04 |
| 사각형 넓이 구하기 와 키오스크 만들기 (0) | 2025.02.04 |