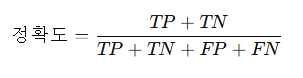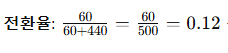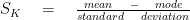아래 내용은 번역한 내용이며, 해당 원서는 아래에 올렸습니다. 프롬프트 엔지니어링저자: Lee Boonstra감사의 말검토자 및 기여자Michael Sherman, Yuan Cao, Erick Armbrust, Anant Nawalgaria, Antonio Gulli, Simone Cammel큐레이터 및 편집자Antonio Gulli, Anant Nawalgaria, Grace Mollison기술 문서 작성자Joey Haymaker디자이너Michael Lanning목차서론프롬프트 엔지니어링LLM 출력 구성출력 길이샘플링 제어온도Top-K 및 Top-P통합하기프롬프트 기술일반 프롬프트 / 제로샷원샷 및 퓨샷시스템, 문맥 및 역할 프롬프트시스템 프롬프트역할 프롬프트문맥 프롬프트Step-back 프롬프트Cha..