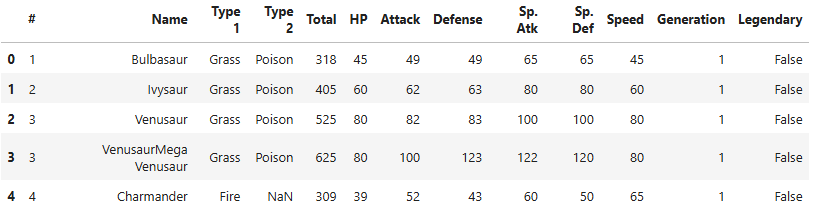
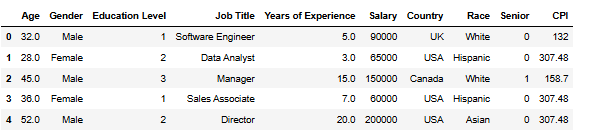
이번에는 pandas의 문법과 다양한 메서드를 활용해 본 적이 있고, 코드를 보면 어느 정도 이해할 수 있습니다.matplotlib을 활용해서 데이터 시각화를 해본 적이 있고, 코드를 보면 어느 정도 이해할 수 있습니다.데이터셋을 train/test 데이터셋으로 나누어서 모델을 학습 및 검증해본 경험이 있다.목표다양한 피처가 있는 데이터셋을 밑바닥부터 샅샅이 뜯어보고, 전설의 포켓몬을 분류하기 위한 피처에는 무엇이 있는지 생각해 보자.모델 학습을 시작하기 전 모든 컬럼에 대해 그래프 시각화, 피벗 테이블 등을 활용하며 다양한 방법으로 충분한 EDA를 진행하자.모델 학습에 넣기 위해서 전처리가 필요한 범주형/문자열 데이터에 대한 전처리를 원-핫 인코딩 등으로 적절하게 진행.전체 데이터셋을 train/tes..