1. 상관관계와 인과관계
상관 관계
- 양의 상관관계:
- 음의 상관관계
트래픽( ) 과 매출 상관관계는?
트래픽과 매출의 관계
트래픽(방문자 수 또는 유입량)과 매출의 상관관계는 일반적으로 양(+)의 상관관계가 있습니다.
다만, 그 정도는 다음의 조건에 따라 달라질 수 있습니다.
- 유입 트래픽의 품질
- 타겟 고객군의 유입이 많다면 매출과 강한 양의 상관관계를 보인다.
- 무작위로 늘어난 트래픽이라면 매출 상승과의 관련성이 낮을 수 있다.
- 전환율(Conversion Rate)
- 방문자 대비 구매율이 높다면, 트래픽 증가 시 매출이 비례적으로 증가한다.
- 전환율이 낮다면, 트래픽 증가가 곧바로 매출 상승으로 이어지기 어렵다.
- 마케팅 및 판매 전략
- 프로모션, 할인 행사 등 전략적인 마케팅을 통해 유입된 트래픽은 매출 증가와 높은 상관성을 보인다.
결론적으로, 트래픽은 일반적으로 매출과 양의 상관관계를 가지나, 유입 트래픽의 질과 전환율, 마케팅 전략에 따라 상관성의 정도는 다르게 나타날 수 있다.
트래픽과 매출의 관계
트래픽과 매출 사이의 관계는 단순한 선형 관계가 아닌 복잡한 상관관계를 가집니다.
감소하는 수익률
연구에 따르면, 매장 판매량은 트래픽에 대해 감소하는 수익률을 보입니다2. 즉, 트래픽이 증가할수록 매출은 증가하지만 그 증가율은 점차 감소합니다.
노동력의 영향
트래픽이 매출에 미치는 영향은 노동력에 의해 조절됩니다2. 예를 들어:
- 평균적인 트래픽과 노동력 수준에서 시간당 평균 트래픽이 1단위 증가하면 시간당 평균 매출이 $9.97 증가합니다.
- 노동력이 1표준편차 증가하면 트래픽의 한계 수익이 $10.00에서 $11.32로 증가합니다.
전환율 감소
트래픽이 증가함에 따라 전환율(방문자 수 대비 구매 비율)은 감소하는 경향이 있습니다2. 이는 높은 트래픽이 반드시 비례적인 매출 증가로 이어지지 않음을 의미합니다.
트래픽 품질의 중요성
단순히 트래픽 양을 늘리는 것보다 품질 높은 트래픽을 유치하는 것이 더 중요합니다14.
전환율 최적화 전략
트래픽을 매출로 전환하기 위한 몇 가지 전략:
- 이메일 리스트 구축: 잠재 고객과 지속적으로 소통할 수 있는 채널을 만듭니다3.
- 신뢰 요소 추가: 리뷰, 보증, 보안 인증 등을 통해 신뢰를 구축합니다3.
- A/B 테스팅: 웹사이트 요소를 지속적으로 테스트하고 최적화합니다3.
결론적으로, 트래픽과 매출은 양의 상관관계를 가지지만, 그 관계는 선형적이지 않으며 여러 요인에 의해 영향을 받습니다. 단순히 트래픽을 늘리는 것보다는 품질 높은 트래픽을 유치하고 전환율을 최적화하는 것이 더 효과적인 전략입니다.
더 명확하게 보는 방법은?
매출을 더 정확하게 예측하고 분석하기 위해서는 다음과 같은 방법들을 활용할 수 있습니다:
데이터 품질 개선
- 완전하고 정확한 데이터 확보
- CRM 데이터의 정확성과 완전성 확인
- 자동화 도구를 활용한 판매 기록 업데이트
- 데이터 수집 및 검증
- CRM 플랫폼을 통해 판매 데이터에 대한 접근성 확보
- 정기적인 데이터 검증 및 업데이트 프로세스 수립
예측 방법론 개선
- 다양한 예측 모델 활용
- 시계열 분석: 과거 데이터의 패턴, 트렌드, 계절성 파악
- 인과 예측 모델: 마케팅 노력, 가격 변동 등 다양한 변수 고려
- 회귀 예측 모델 적용
- 시장 조건, 고객 심리, 경제 동향 등 다양한 요소 분석
- 변수 간 관계를 통해 더 정확한 예측 도출
프로세스 최적화
- 명확한 예측 프로세스 정의
- 목표 설정 및 시장 이해
- 적절한 예측 방법 선택
- 정기적인 검토 일정 수립
- 일관된 방법론 적용
- 모든 영업 담당자가 예측 모델을 이해하고 적용하도록 교육
- 예측 정확도와 KPI 연계
- 정기적인 예측 모델 검토 및 개선
- 주기적으로 예측 모델의 효과성 평가
- 비즈니스 변화에 따라 유연하게 접근 방식 조정
고급 분석 기법 도입
- 다변량 분석 활용
- 제품 가격, 고객 행동, 시장 조건 등 다양한 변수 고려
- 회귀 분석, 머신 러닝, AI 기술 활용
- 대화 기반 예측 방법 적용
- 영업 상호작용에서 얻은 정성적 데이터 활용
- 고객 의도, 참여도, 잠재적 장애물 파악
이러한 방법들을 종합적으로 적용하면 매출 예측의 정확성을 크게 향상시킬 수 있습니다. 지속적인 데이터 관리와 예측 모델의 개선, 그리고 다양한 분석 기법의 활용이 중요합니다
인과관계
Prophet은 페이스북에서 공개한 시계열 예측 라이브러리
인과관계의 기본 원리
- 원인은 결과의 확률을 변화시킵니다
- 원인은 시간적으로 결과보다 선행해야 합니다.
- 외부 요인의 영향을 배제해야 합니다.
인과관계 추론 방법
- 실험적 연구: 가장 효과적인 방법으로, 무작위 대조 실험(RCT)을 통해 인과관계를 입증합니다.
- 관찰 연구: 실험이 불가능한 경우 사용되며, 다음과 같은 기법들이 활용됩니다:
- 도구변수법
- 이중차이 분석
- 성향 점수 매칭
- 확률적 인과관계 모델: Judea Pearl의 do-연산자를 사용하여 인과관계를 표현합니다.
Pr(effect∣do(cause))>Pr(effect∣do( cause))
주의사항
- 상관관계와 인과관계의 구분: "상관관계가 인과관계를 의미하지는 않는다"는 원칙을 항상 명심해야 합니다.
- 허위 상관관계(Spurious correlation) 주의: 큰 데이터셋에서 우연히 나타날 수 있는 거짓 상관관계에 주의해야 합니다.
- 방향성 문제: 인과관계의 방향을 명확히 파악해야 하며, 역인과관계의 가능성도 고려해야 합니다.
인과관계를 정확히 파악하는 것은 통계학의 중요한 과제이며, 이를 위해 다양한 방법론과 주의 깊은 해석이 필요합니다.
상관관계, 인과관계 분석방법
1. 상관관계(Correlation) 분석 방법
상관관계란 두 변수 간의 관련성을 의미하며, 한 변수가 변할 때 다른 변수가 어떤 경향을 보이는지를 나타냅니다.
(1) 정의
- 두 변수가 서로 어떻게 관련되는지의 강도와 방향을 나타냄
- 원인과 결과 관계는 명확하지 않음(단순 관련성만을 나타냄)
(2) 분석 방법
- 산점도(Scatter Plot)
- 두 변수의 관계를 시각적으로 표현해 직관적으로 파악하는 방법
- 상관계수(Correlation Coefficient)
- 대표적인 계수: 피어슨(Pearson), 스피어만(Spearman), 켄달(Kendall)
- –1 ≤ r ≤ 1, ±1에 가까울수록 상관이 강함
- 0에 가까울수록 상관관계 없음
- 1에 가까움: 강한 양(+)의 상관
- 1에 가까움: 강한 음(-)의 상관
(3) 주의사항
- 상관관계는 인과관계를 나타내지 않으며, 높은 상관이 있다고 해서 원인-결과로 해석하면 안됨.
2. 인과관계(Causation) 분석 방법
인과관계는 한 변수가 직접적으로 다른 변수에 영향을 주는 관계로, 원인과 결과가 명확하게 구분됩니다.
(1) 정의
- 한 변수(원인)가 변화함으로써 다른 변수(결과)에 영향을 주는 관계
- 원인과 결과의 순서가 명확
(2) 분석 방법
- 실험적 방법 (Experimental Methods)
- A/B 테스트, 무작위 대조시험(Randomized Controlled Trials, RCT)
- 변수를 인위적으로 통제하여 원인과 결과를 명확히 함
- 준실험적 방법 (Quasi-Experimental Methods)
- 실제 환경에서 랜덤화가 불가능할 때 사용 (사전·사후 비교법 등)
- 관찰적 방법 (Observational Methods)
- 회귀분석, 인과추론(예: Propensity Score Matching, Difference-in-Differences, DID)
- 교란변수(confounding)를 통제하여 실제적인 인과성을 확인
(3) 인과관계 검증 기준 (힐의 기준, Hill’s Criteria)
- 시간적 선후관계 (원인이 결과보다 먼저 발생해야 함)
- 강도 (원인이 결과에 미치는 영향력이 충분히 큼)
- 일관성 (다른 연구에서도 동일한 결과가 반복됨)
- 특이성 (특정 원인이 특정 결과만을 야기함)
- 생물학적 타당성 (논리적, 이론적으로 설명 가능)
- 용량-반응 관계 (원인의 크기나 양이 증가할수록 결과의 변화도 증가함)
3. 두 관계의 구분 예시
- 상관관계 예시:→ 단순한 상관관계 (더운 날씨가 숨겨진 변수)
- "아이스크림 판매량이 증가하면 익사 사고도 증가한다."
- 인과관계 예시:→ 입증된 인과관계 (많은 연구와 실험을 통해 증명됨)
- "흡연량이 증가하면 폐암 발병률도 증가한다."
| 항목 | 상관관계 | 인과관계 |
| 핵심 | 관련성 | 원인과 결과 |
| 방향성 | 불명확 | 명확 |
| 분석방법 | 산점도, 상관계수 | 실험(AB테스트), 준실험(DID), 인과추론(PSM) |
| 검증기준 | 상관계수(r값) | 힐의 기준 (Hill’s Criteria) |
| 해석주의 | 인과관계로 잘못 해석하면 안됨 | 교란변수를 반드시 통제해야 함 |
이와 같이 두 관계를 정확히 구분하고 분석하면 데이터 해석의 정확도와 신뢰도를 높일 수 있다.
그럼 상관관계와 인과관계를 분석할 때 교란변수를 통제하는 가장 탁월하고 추천되는 방법은?
1. 교란변수의 개념
- 교란변수(confounding)란 원인과 결과 변수 모두에 영향을 미치는 제3의 변수입니다.
- 교란변수가 존재하면 잘못된 인과관계가 도출될 수 있습니다.
예시: "커피 소비가 심장병을 일으킨다."
실제로는 흡연이라는 교란변수가 존재하여 잘못된 인과관계를 초래할 수 있습니다.
2. 교란변수를 통제하는 탁월한 방법
다음의 5가지 방법은 교란변수 통제에 가장 효과적이고 널리 추천되는 방법입니다.
(1) 무작위 대조시험(Randomized Controlled Trial, RCT)
- 정의: 실험 참가자를 실험군과 대조군에 무작위로 배정하여 비교하는 방법
- 장점:
- 모든 알려지거나 알려지지 않은 교란변수를 자동으로 통제 가능
- 인과관계 입증에 가장 강력한 방법
- 단점:
- 현실적으로 비용, 윤리적 문제 등으로 제한될 수 있음
추천 정도: 매우 탁월(가장 이상적이고 권장)
1. 무작위 대조시험(RCT)이란?
2. RCT의 핵심 원리
3. 무작위 배정(Randomization)의 효과 (핵심!)
4. RCT를 활용한 구체적인 예시
5. RCT의 장단점 요약 5. RCT를 할 수 없을 때의 대안방법
[ 정리 ]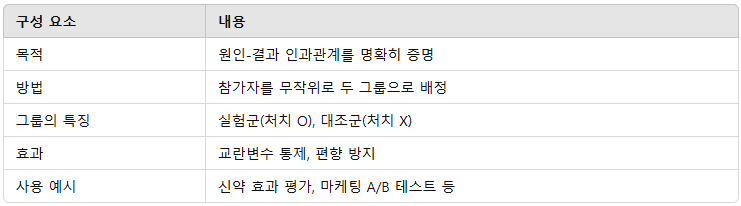 RCT는 이와 같은 과정을 통해 신뢰할 수 있는 인과관계를 확인하는 가장 명확하고 확실한 방법입니다. |
(2) 성향점수 매칭(Propensity Score Matching, PSM)
- 정의: 성향점수(특정 처치 받을 확률)를 기반으로 실험군과 유사한 대조군을 매칭하는 방법
- 장점:
- 관찰 연구 데이터에서도 사용 가능
- 교란변수를 효과적으로 통제 가능
- 단점:
- 관측된 교란변수만 통제할 수 있음(미관측 변수 통제 불가)
추천 정도: 매우 추천(관찰 연구에 효과적)
(3) 차분법(Difference-in-Differences, DID)
- 정의: 특정 사건 전후 실험군과 대조군의 변화 차이를 비교하여 효과를 분석하는 방법
- 장점:
- 시간적으로 고정된 교란변수를 제거 가능
- 단점:
- 시간이 흐름에 따라 변하는 교란변수(time-varying confounder)는 통제 어려움
추천 정도: 추천(정책 효과, 시계열 분석에 적합)
(4) 도구변수법(Instrumental Variable, IV)
- 정의: 교란변수의 영향을 받지 않고 원인 변수에만 영향을 미치는 도구변수를 사용하여 순수한 인과효과를 추정하는 방법
- 장점:
- 관측되지 않은 교란변수를 통제할 수 있음
- 단점:
- 적절한 도구변수를 찾기가 어려움
추천 정도: 추천(관측되지 않은 교란변수가 의심될 때 유용)
(5) 회귀분석을 통한 통계적 통제
- 정의: 교란변수를 독립변수로 추가하여 분석에서 그 영향을 통제하는 방법
- 장점:
- 사용이 쉽고 직관적
- 단점:
- 누락된 교란변수로 인한 편향 가능성이 있음
추천 정도: 기본적으로 활용(쉬우나 완벽한 통제 어려움)
3. 추천 순위 요약표
순위 분석 방법 이유 및 활용도
| 1위 | 무작위 대조시험(RCT) | 완벽한 통제 가능, 가장 이상적 |
| 2위 | 성향점수 매칭(PSM) | 관찰 연구에서 가장 추천 |
| 3위 | 차분법(DID) | 정책이나 시점 비교에 효과적 |
| 4위 | 도구변수법(IV) | 미관측 변수 통제에 유용 |
| 5위 | 회귀분석 | 간편하지만 일부 제한적 통제 가능 |
결론
- 가장 탁월한 방법은 무작위 대조시험(RCT)입니다.
- 현실적 제한이 있으면 성향점수 매칭(PSM) 또는 차분법(DID)을 활용하는 것이 좋습니다.
- 관측되지 않은 교란변수가 있다면 도구변수(IV) 방법을 고려하는 것이 좋습니다.
※ 장바구니는 모두 회사에서 중요하게 생각하는 요소이다. 구매와 연관이 깊음
2. 회귀모형 익히기
회귀모형(Regression Model)은 데이터 분석에서 특정 변수 간의 관계를 분석하고 예측하는 데 사용되는 통계적 방법입니다.
1. 회귀모형의 정의
- 종속변수(결과값)에 영향을 주는 하나 이상의 독립변수(설명변수)와의 관계를 수학적 방정식으로 표현하여 예측하는 모델입니다.
- 주로 연속형 데이터를 예측할 때 사용합니다.
2. 회귀모형의 종류
- 단순 선형회귀(Simple Linear Regression)
- 하나의 독립변수와 하나의 종속변수 간의 관계를 직선(선형)으로 표현
- 식: Y=a+bX+e
- Y=a+bX+eY = a + bX + e
- 다중 선형회귀(Multiple Linear Regression)
- 여러 개의 독립변수가 하나의 종속변수에 영향을 미칠 때 사용하는 모형
- 식:
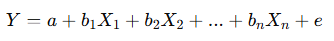
- 로지스틱 회귀(Logistic Regression)
- 종속변수가 범주형(이진 분류 등)일 때 사용
- 식:

3. 회귀모형의 목적과 사용처
- 예측(Prediction): 미래의 수치를 예측하거나 미지의 값을 추정
- 설명(Explanation): 변수 간 영향력을 분석하여 특정 현상을 설명하거나 이해
4. 회귀모형의 가정
- 선형성(Linearity): 독립변수와 종속변수 간 관계가 선형이어야 함
- 정규성(Normality): 오차항(residual)이 정규분포를 따라야 함
- 등분산성(Homoscedasticity): 오차항의 분산이 일정해야 함
- 독립성(Independence): 각 관측값 간 독립성을 유지해야 함
- 다중공선성(Multicollinearity): 독립변수 간 강한 상관관계를 피해야 함
5. 평가 지표
- 결정계수(R²): 독립변수가 종속변수를 얼마나 설명하는지 나타내는 값 (높을수록 좋음)
- 평균제곱오차(MSE), 평균절대오차(MAE), RMSE: 예측의 정확도를 평가하는 지표 (낮을수록 좋음)
6. 실제 활용 예시
- 부동산 가격 예측
- 매출액 예측
- 고객 구매액 예측
- 질병 위험도 예측(로지스틱 회귀 등)
회귀모형을 통해 데이터 간의 관계를 분석하고 예측하는 것은 데이터 분석의 가장 기초적이고 중요한 방법입니다.
복잡한 문제 해결 과정에서 필요한 분석적 사고와 창의적 접근의 중요성
- 표면적 현상에 현혹되지 말 것: 문제의 근본 원인은 겉으로 보이는 것과 다를 수 있습니다.
- 데이터 기반 접근: 객관적인 데이터 수집과 분석이 문제 해결의 열쇠입니다.
- 열린 사고방식: 비논리적으로 보이는 문제도 진지하게 접근해야 합니다.
- 종합적 시각: 문제를 다각도로 바라보고 여러 요소를 고려해야 합니다.
데이터 분석 관점에서 예측과 추론의 차이를 구분해야
회귀모형을 평가할 때 사용되는 대표적인 지표인 R², MSE, MAE, RMSE
1. R² (결정계수)
(1) 정의
- 독립변수들이 종속변수를 얼마나 잘 설명하는지를 나타내는 지표입니다.
- 설명력 지표이며, 결정계수(Coefficient of Determination)라고 합니다.
(2) 공식

- SSE(잔차제곱합): 실제값과 예측값 차이의 제곱의 합
- SST(총변동): 실제값이 평균에서 얼마나 퍼져있는지 나타냄
(3) 해석법
- 0 ~ 1 사이의 값을 가지며, 1에 가까울수록 모형의 설명력이 높음.
- R2=0.8R^2 = 0.8R2=0.8 → "모형이 전체 변동의 80%를 설명한다."
2. MSE (Mean Squared Error, 평균 제곱 오차)
(1) 정의
- 예측값과 실제값의 차이를 제곱하여 평균을 낸 값입니다.
- 예측값과 실제값 간의 오차 크기를 나타냅니다.
(2) 공식

(2) 특징
- 오차가 클수록 더 크게 반영됨(큰 오차에 민감)
- 제곱된 단위이므로 직관적으로 이해하기 어려울 수 있음
3. MAE (Mean Absolute Error, 평균 절대 오차)
(1) 정의
- 예측값과 실제값의 차이에 절댓값을 취해 평균을 구한 값
- 오차를 절댓값으로 다루어 직관적으로 이해하기 쉬움
(2) 공식

(3) 특징
- 실제 단위로 표현되어 직관적임.
- 이상치나 큰 오차에 상대적으로 덜 민감.
4. RMSE (Root Mean Squared Error, 평균 제곱근 오차)
(1) 정의
- MSE 값에 제곱근(루트)을 취해 원래 단위로 변환한 지표입니다.
(2) 공식
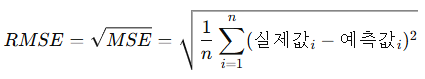
(3) 특징
- MSE보다 직관적 (실제 데이터와 같은 단위로 표시됨)
- 큰 오차에 민감함 (MSE의 특징 유지)
요약 정리 표

요약 정리
- 모형의 설명력을 평가할 땐 → R²
- 모형의 정확도를 평가할 때는 주로 RMSE나 MAE를 사용
- 큰 오차에 민감한 평가 필요 → RMSE (대표 추천)
- 큰 오차 민감도 낮추고 싶다면 → MAE 선택
데이터로 가치를 만드는 Steven, Follow on LinkedIn
'데이터 분석가:Applied Data Analytics' 카테고리의 다른 글
| 캔바(Canva)란? (0) | 2025.03.06 |
|---|---|
| 데이터 기반 의사결정을 위한 확률 및 분포 5-2] (0) | 2025.03.06 |
| 구글 코렙 연결(Google Colab 연동) (0) | 2025.03.06 |
| 구글 코렙 한글적용(Google Colab 한글) (0) | 2025.03.06 |
| 데이터 기반 의사결정을 위한 확률 및 분포 4-2] (0) | 2025.03.05 |