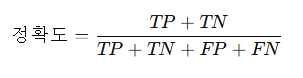1. 혼동행렬(Confusion Matrix)의 개념혼동행렬은 분류 모델이 얼마나 잘 예측했는지 확인하는 표 형태의 도구입니다.분류 결과를 실제값과 예측값에 따라 네 가지로 구분하여 표현합니다.구분예측 Positive (P)예측 Negative (N)실제 Positive (P)TP (True Positive, 진짜 양성)FN (False Negative, 가짜 음성)실제 Negative (N)FP (False Positive, 가짜 양성)TN (True Negative, 진짜 음성)TP: 실제로도 양성, 예측도 양성 (정답)TN: 실제로도 음성, 예측도 음성 (정답)FP: 실제로는 음성이나, 양성으로 잘못 예측한 경우 (오류)FN: 실제로는 양성이나, 음성으로 잘못 예측한 경우 (오류)2. 평가 지표의 ..