#군집 k-Means
# 기본 라이브러리 불러오기
import pandas as pd
import matplotlib.pyplot as plt
'''
[Step 1] 데이터 준비
'''
# Wholesale customers 데이터셋 가져오기 (출처: UCI ML Repository)
00292/Wholesale%20customers%20data.csv'
df = pd.read_csv(uci_path, header=0)
'''
[Step 2] 데이터 탐색
'''
# 데이터 살펴보기
df.head()

# 데이터 자료형 확인
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 440 entries, 0 to 439
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Channel 440 non-null int64
1 Region 440 non-null int64
2 Fresh 440 non-null int64
3 Milk 440 non-null int64
4 Grocery 440 non-null int64
5 Frozen 440 non-null int64
6 Detergents_Paper 440 non-null int64
7 Delicassen 440 non-null int64
dtypes: int64(8)
memory usage: 27.6 KB# 데이터 통계 요약정보 확인
df.describe()

# 누락 데이터 확인
df.isnull().sum()
Channel 0
Region 0
Fresh 0
Milk 0
Grocery 0
Frozen 0
Detergents_Paper 0
Delicassen 0
dtype: int64# 중복 데이터 확인
df.duplicated().sum()
0'''
[Step 3] 데이터 전처리
'''
# 분석에 사용할 속성을 선택
X = df.iloc[:, :]
print(X[:5])
Channel Region Fresh Milk Grocery Frozen Detergents_Paper Delicassen
0 2 3 12669 9656 7561 214 2674 1338
1 2 3 7057 9810 9568 1762 3293 1776
2 2 3 6353 8808 7684 2405 3516 7844
3 1 3 13265 1196 4221 6404 507 1788
4 2 3 22615 5410 7198 3915 1777 5185# 설명 변수 데이터를 정규화
from sklearn import preprocessing
X_std = preprocessing.StandardScaler().fit_transform(X)
X_std[:5]
array([[ 1.44865163, 0.59066829, 0.05293319, 0.52356777, -0.04111489,
-0.58936716, -0.04356873, -0.06633906],
[ 1.44865163, 0.59066829, -0.39130197, 0.54445767, 0.17031835,
-0.27013618, 0.08640684, 0.08915105],
[ 1.44865163, 0.59066829, -0.44702926, 0.40853771, -0.0281571 ,
-0.13753572, 0.13323164, 2.24329255],
[-0.69029709, 0.59066829, 0.10011141, -0.62401993, -0.3929769 ,
0.6871443 , -0.49858822, 0.09341105],
[ 1.44865163, 0.59066829, 0.84023948, -0.05239645, -0.07935618,
0.17385884, -0.23191782, 1.29934689]])'''
[Step 4] k-means 군집 모형 - sklearn 사용
'''
# sklearn 라이브러리에서 cluster 군집 모형 가져오기
from sklearn import cluster
# 모형 객체 생성
kmeans = cluster.KMeans(init='k-means++', n_clusters=5, n_init=10)
# 모형 학습
kmeans.fit(X_std)
# 예측 (군집)
cluster_label = kmeans.labels_
print(cluster_label)
[1 1 1 2 1 1 1 1 2 1 1 1 1 1 1 2 1 2 1 2 1 2 2 1 1 1 2 2 1 2 2 2 2 2 2 1 2
1 1 2 2 2 1 1 1 1 1 4 1 1 2 2 1 1 2 2 4 1 2 2 1 4 1 1 2 4 2 1 2 2 2 2 2 1
1 2 2 1 2 2 2 1 1 2 1 4 4 2 2 2 2 2 4 2 1 2 1 2 2 2 1 1 1 2 2 2 1 1 1 1 2
1 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2
2 2 2 2 2 2 2 1 1 2 1 1 1 2 2 1 1 1 1 2 2 2 1 1 2 1 2 1 2 2 2 2 2 2 2 3 2
2 2 2 1 1 2 2 2 1 2 2 0 1 0 0 1 1 0 0 0 1 0 0 0 1 0 4 0 0 1 0 1 0 1 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 4 0 0 0 0 0 0 0
0 0 0 0 0 1 0 1 0 1 0 0 0 0 2 2 2 2 2 2 1 2 1 2 2 2 2 2 2 2 2 2 2 2 1 0 1
0 1 1 0 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 0 0 0 1 0 0 0 0 0 3 0 0 0 0 0 1 0
4 0 1 0 0 0 0 1 1 2 1 2 2 1 1 2 1 2 1 2 1 2 2 2 1 2 2 2 2 2 2 2 1 2 2 2 2
2 2 2 1 2 2 1 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2
1 1 2 2 2 2 2 2 1 1 2 1 2 2 1 2 1 1 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2]# 예측 결과를 데이터프레임에 추가
df['Cluster'] = cluster_label
df.head()

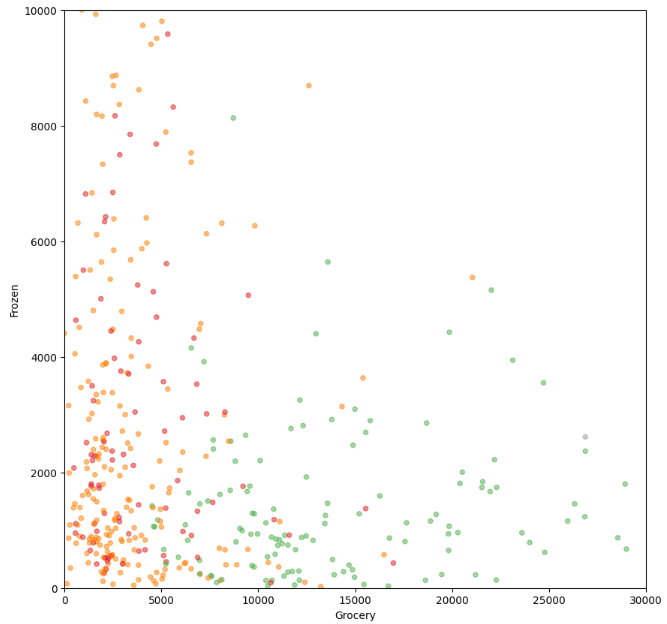
# 그래프로 표현 - 시각화
df.plot(kind='scatter', x='Grocery', y='Frozen', c='Cluster', cmap='Set1',
colorbar=False, alpha=0.5, figsize=(5, 5));
df.plot(kind='scatter', x='Milk', y='Delicassen', c='Cluster', cmap='Set1',
colorbar=True, alpha=0.5, figsize=(5, 5));


# xlim, ylim 제한 - 값이 몰려 있는 구간을 자세하게 분석
ax1 = df.plot(kind='scatter', x='Grocery', y='Frozen', c='Cluster', cmap='Set1',
colorbar=False, alpha=0.5, figsize=(10, 10))
ax2 = df.plot(kind='scatter', x='Milk', y='Delicassen', c='Cluster', cmap='Set1',
colorbar=True, alpha=0.5, figsize=(10, 10))
ax1.set_xlim(0, 30000)
ax1.set_ylim(0, 10000)
ax2.set_xlim(0, 30000)
ax2.set_ylim(0, 10000)
plt.show()

# DBSCAN
# 기본 라이브러리 불러오기
import pandas as pd
import folium
# 디스플레이 옵션 설정
pd.set_option('display.width', None) # 출력화면의 너비
pd.set_option('display.max_rows', 100) # 출력할 행의 개수 한도
pd.set_option('display.max_columns', 10) # 출력할 열의 개수 한도
pd.set_option('display.max_colwidth', 20) # 출력할 열의 너비
pd.set_option('display.unicode.east_asian_width', True) # 유니코드 사용 너비 조정
'''
[Step 1] 데이터 준비
'''
# 서울시내 중학교 진학률 데이터셋
file_path = 'data/07/middle_shcool_graduates_report.xlsx'
df = pd.read_excel(file_path)
# 열 이름 배열을 출력
print(df.columns.values)
['지역' '학교명' '코드' '유형' '주야' '남학생수' '여학생수' '일반고' '특성화고' '과학고' '외고_국제고'
'예고_체고' '마이스터고' '자사고' '자공고' '기타진학' '취업' '미상' '위도' '경도']'''
[Step 2] 데이터 탐색
'''
# 데이터 살펴보기
df.head()

# 데이터 자료형 확인
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 415 entries, 0 to 414
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역 415 non-null object
1 학교명 415 non-null object
2 코드 415 non-null int64
3 유형 415 non-null object
4 주야 415 non-null object
5 남학생수 415 non-null int64
6 여학생수 415 non-null int64
7 일반고 415 non-null float64
8 특성화고 415 non-null float64
9 과학고 415 non-null float64
10 외고_국제고 415 non-null float64
11 예고_체고 415 non-null float64
12 마이스터고 415 non-null float64
13 자사고 415 non-null float64
14 자공고 415 non-null float64
15 기타진학 415 non-null float64
16 취업 415 non-null int64
17 미상 415 non-null float64
18 위도 415 non-null float64
19 경도 415 non-null float64
dtypes: float64(12), int64(4), object(4)
memory usage: 65.0+ KB# 데이터 통계 요약정보 확인
df.describe()

# 누락 데이터 확인
df.isnull().sum().sum()
0# 중복 데이터 확인
df.duplicated().sum()
0# 지도에 위치 표시 *** Stamen Terrain 타일의 경우 별도의 인증을 요구하므로 OpenTopoMap 타일을 사용하는 것으로 수정 ***
attr = (
'Map data: © OpenStreetMap contributors, SRTM | Map style: © OpenTopoMap (CC-BY-SA)'
)
tiles = 'https://{s}.tile.opentopomap.org/{z}/{x}/{y}.png'
mschool_map = folium.Map(location=[37.55,126.98], tiles=tiles, attr=attr,
zoom_start=12)
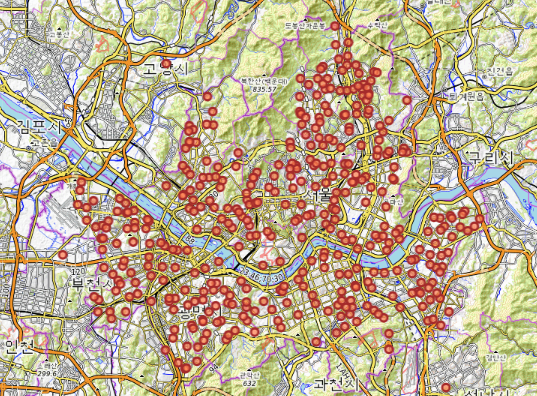
# 중학교 위치정보를 CircleMarker로 표시
for name, lat, lng in zip(df['학교명'], df['위도'], df['경도']):
folium.CircleMarker([lat, lng],
radius=5, # 원의 반지름
color='brown', # 원의 둘레 색상
fill=True,
fill_color='coral', # 원을 채우는 색
fill_opacity=0.7, # 투명도
popup=name
).add_to(mschool_map)
mschool_map
# 지도를 html 파일로 저장하기
mschool_map.save('data/07/action_seoul_mschool_location.html')
'''
[Step 3] 데이터 전처리
'''
# 고유값의 개수
print(df['지역'].nunique())
print(df['코드'].nunique())
print(df['유형'].nunique())
print(df['주야'].nunique())
25
3
3
1# 원-핫 인코딩 적용
df_encoded = pd.get_dummies(df, columns=['지역', '코드', '유형', '주야'])
df_encoded.head()

'''
[Step 4] DBSCAN 군집 모형 - sklearn 사용
'''
# sklearn 라이브러리에서 cluster 군집 모형 가져오기
from sklearn import cluster
from sklearn import preprocessing
# 분석에 사용할 속성을 선택
train_features = ['과학고', '외고_국제고', '자사고', '자공고',
'유형_공립', '유형_국립', '유형_사립',]
X = df_encoded.loc[:, train_features]
# 설명 변수 데이터를 정규화
X = preprocessing.StandardScaler().fit_transform(X)
# DBSCAN 모형 객체 생성
dbm = cluster.DBSCAN(eps=0.2, min_samples=5)
# 모형 학습
dbm.fit(X)
# 예측 (군집)
cluster_label = dbm.labels_
print(cluster_label)
[-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 4 0
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0 -1 -1 -1 0 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 2 -1 -1 -1 0 -1 0 -1 -1 -1 0 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0
-1 -1 0 -1 -1 -1 -1 1 0 -1 -1 0 -1 -1 -1 2 -1 -1 -1 -1 -1 -1 1 -1
-1 -1 -1 0 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0 -1 -1 -1 -1
-1 2 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 0 -1 -1 -1 3 -1 -1 -1 -1 -1 -1 -1 0 -1 -1 0 -1 -1 -1 -1 -1
2 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 0 -1 -1 -1 -1 0 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 0 -1 -1 -1 -1 -1 -1 -1 -1 4 -1 -1 4 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 0 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 4 -1 -1 -1 0 -1 4 1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 2 -1 -1 -1 0 -1 -1
5 5 5 3 3 3 3 1 3 3 3 3 1 1 1 1 3 3 1 3 3 3 3 3
1 1 5 5 3 3 -1]# 예측 결과를 데이터프레임에 추가
df_encoded['Cluster'] = cluster_label
df_encoded.head()

# 클러스터 값으로 그룹화하고, 그룹별로 내용 출력 (첫 5행만 출력)
grouped_cols = ['학교명', '과학고', '외고_국제고', '자사고',]
grouped = df_encoded.groupby('Cluster')
for key, group in grouped:
print('* key :', key)
print('* number :', len(group))
print(group.loc[:, grouped_cols].head())
print('\n')
* key : -1
* number : 347
학교명 과학고 외고_국제고 자사고
0 서울대학교사범대학부설중학교..... 0.018 0.007 0.227
1 서울대학교사범대학부설여자중학교... 0.000 0.035 0.043
2 개원중학교 0.009 0.012 0.090
3 개포중학교 0.013 0.013 0.065
4 경원중학교 0.007 0.010 0.282
* key : 0
* number : 24
학교명 과학고 외고_국제고 자사고
47 둔촌중학교 0.0 0.010 0.026
58 성내중학교 0.0 0.013 0.026
62 신명중학교 0.0 0.009 0.031
78 한산중학교 0.0 0.012 0.052
80 강신중학교 0.0 0.012 0.039
* key : 1
* number : 11
학교명 과학고 외고_국제고 자사고
103 신원중학교 0.0 0.0 0.006
118 개봉중학교 0.0 0.0 0.012
356 서울체육중학교 0.0 0.0 0.000
391 서울광진학교 0.0 0.0 0.000
396 서울정문학교 0.0 0.0 0.000
* key : 2
* number : 5
학교명 과학고 외고_국제고 자사고
74 천일중학교 0.0 0.003 0.023
111 양천중학교 0.0 0.003 0.017
145 오류중학교 0.0 0.004 0.026
192 미성중학교 0.0 0.005 0.023
377 천왕중학교 0.0 0.004 0.032
* key : 3
* number : 18
학교명 과학고 외고_국제고 자사고
175 혜원여자중학교 0.0 0.0 0.004
387 교남학교 0.0 0.0 0.000
388 다니엘학교 0.0 0.0 0.000
389 밀알학교 0.0 0.0 0.000
390 새롬학교 0.0 0.0 0.000
* key : 4
* number : 5
학교명 과학고 외고_국제고 자사고
46 동신중학교 0.0 0.0 0.044
279 중앙여자중학교 0.0 0.0 0.036
282 한성중학교 0.0 0.0 0.042
349 장충중학교 0.0 0.0 0.038
355 환일중학교 0.0 0.0 0.027
* key : 5
* number : 5
학교명 과학고 외고_국제고 자사고
384 서울농학교 0.0 0.0 0.0
385 한국우진학교 0.0 0.0 0.0
386 서울맹학교 0.0 0.0 0.0
410 국립국악중학교 0.0 0.0 0.0
411 국립전통예술중학교 0.0 0.0 0.0# 그래프로 표현 - 시각화
colors = {-1:'gray', 0:'coral', 1:'blue', 2:'green', 3:'red', 4:'purple',
5:'orange', 6:'brown', 7:'brick', 8:'yellow', 9:'magenta', 10:'cyan', 11:'tan'}
cluster_map = folium.Map(location=[37.55,126.98], tiles=tiles, attr=attr,
zoom_start=12)
for name, lat, lng, clus in zip(df_encoded['학교명'], df_encoded['위도'],
df_encoded['경도'], df_encoded['Cluster']):
folium.CircleMarker([lat, lng],
radius=5, # 원의 반지름
color=colors[clus], # 원의 둘레 색상
fill=True,
fill_color=colors[clus], # 원을 채우는 색
fill_opacity=0.7, # 투명도
popup=name
).add_to(cluster_map)
cluster_map

# 지도를 html 파일로 저장하기
cluster_map.save('data/07/action_seoul_mschool_cluster.html')
참고로 이곳에 나오는 'data/07/action_seoul_mschool_cluster.html' 파일 경로는 본인의 데이터가 있는 경로, 또는 파일을 저장할 본인의 컴퓨터 경로를 의미 합니다 가급적이면 한글이 포함안된 폴더로 설정하세요.
'데이터 분석가:Applied Data Analytics > 판다스 데이터분석' 카테고리의 다른 글
| 5. Feature Engineering - 스피드 데이팅 데이터 다루기 (0) | 2025.02.18 |
|---|---|
| Feature Engineering (1) | 2025.02.18 |
| 데이터분석머신러닝-실습(KNN, SVM) (0) | 2025.02.17 |
| 머신러닝(Machine Learning, ML)-실습 (1) | 2025.02.14 |
| 머신러닝(Machine Learning, ML)-용어편 (0) | 2025.02.14 |