1. CSV 파일을 데이터 웨어하우스(예: Google BigQuery)로 업로드
A. Google BigQuery에 CSV 파일 업로드
- BigQuery 콘솔 접속:
Google Cloud Console에서 BigQuery 페이지로 이동합니다. - 데이터셋 생성:
CSV 파일을 업로드할 데이터셋이 없다면, 새 데이터셋을 생성합니다.- BigQuery 왼쪽 패널에서 프로젝트명을 클릭하고 **"데이터셋 만들기"**를 선택합니다.
- 데이터셋 ID, 위치 및 기타 옵션을 설정한 후 생성합니다.
- 테이블 생성 및 CSV 파일 업로드:
- 생성한 데이터셋 내에서 "테이블 만들기" 버튼을 클릭합니다.
- 소스 유형(Source)에서 "파일 업로드"를 선택하고 CSV 파일을 선택합니다.
- 파일 형식(File format)은 CSV로 지정합니다.
- 대상 테이블(Destination table) 정보(프로젝트, 데이터셋, 테이블 이름)를 입력합니다.
- 스키마(Schema)는 자동 감지(auto detect)를 활성화하거나 직접 각 컬럼(예: first_visit_date, days_since_first_visit, n_users 등)의 이름과 데이터 타입을 지정합니다.
- "테이블 만들기" 버튼을 클릭하여 CSV 파일을 BigQuery 테이블로 업로드합니다.
2. BigQuery와 Looker 연결 설정
B. Looker에서 데이터 커넥션 설정하기
- Looker Admin 접근:
Looker 인스턴스에 로그인 후, 상단 또는 좌측 메뉴에서 "Admin" (또는 "관리자") 메뉴로 이동합니다. - Connections 설정:
- "Connections" 탭을 선택하고 "New Connection" (새 연결 추가)을 클릭합니다.
- 연결 유형(Type)에서 BigQuery를 선택합니다.
- 필요한 연결 정보를 입력합니다.
- 예를 들어, Project ID, Dataset, 인증 정보(서비스 계정 키 파일 등)를 입력합니다.
- 연결 테스트 후 "Save" 하여 연결 설정을 완료합니다.
3. LookML 프로젝트 구성 (모델 및 뷰 정의)
C. LookML 프로젝트에서 CSV 기반 테이블을 참조하는 LookML View 생성
- 새 LookML 프로젝트 생성:
- Looker IDE에서 새로운 프로젝트를 생성합니다.
- 프로젝트 이름(예: cohort_analysis)을 지정합니다.
- View 파일 생성:
- 프로젝트 내에서 새 View 파일을 생성합니다. 예: cohort_data.view.lkml
- 업로드한 BigQuery 테이블을 참조하도록 view를 정의합니다.
view: cohort_data {
sql_table_name: your_dataset.your_table ;; # 여기서 your_dataset과 your_table은 BigQuery의 실제 이름
dimension: first_visit_date {
type: date
sql: ${TABLE}.first_visit_date ;;
}
dimension: days_since_first_visit {
type: number
sql: ${TABLE}.days_since_first_visit ;;
}
measure: n_users {
type: sum
sql: ${TABLE}.n_users ;;
}
# 추가 차원(예: retention_rate 등)을 계산 필드로 정의할 수 있습니다.
} - Model 파일에서 Explore 추가:
- 새 Model 파일(ex. cohort_analysis.model.lkml)을 만들어서, 위에서 생성한 view를 포함시키고 explore를 정의합니다.
connection: "bigquery_connection_name" # Admin에서 만든 연결 이름
include: "/views/cohort_data.view.lkml"
explore: cohort_data {
# 기본 필드 및 필터 설정 가능
}
4. Looker에서 데이터 탐색 및 시각화
D. Looker Explore를 활용한 시각화 생성
- Explore 진입:
- Looker 상단 메뉴 또는 탐색 메뉴에서 방금 만든 explore (cohort_data)를 선택합니다.
- 시각화 생성:
- 히트맵 차트:
- x축: days_since_first_visit (첫 방문 후 경과 일수)
- y축: first_visit_date (코호트, 최초 방문일)
- 표현 값: Retention Rate (%) 또는 n_users를 사용하여 각 셀의 비율 또는 수치를 계산하는 Table Calculation(테이블 계산) 설정
- Looker의 시각화 옵션에서 히트맵(Heatmap)을 선택하고, 필요한 경우 색상 팔레트 등을 조정합니다.
- 선 그래프 (N-day Retention):
- x축: days_since_first_visit
- y축: 계산된 Retention Rate (%) (예: 특정 코호트의 day0 대비 각 일자 비율)
- Looker에서 해당 코호트를 필터로 선택한 후, 선 그래프(Line Chart)를 선택합니다.
- 코호트 차트 (여러 코호트 비교):
- x축: days_since_first_visit
- y축: Retention Rate (%) (또는 n_users)
- 라벨/세그먼트: first_visit_date를 사용하여 각 코호트를 구분합니다.
- 여러 코호트를 한 번에 표시할 수 있도록 라인 차트에 first_visit_date를 분할 차원(Dimension)으로 추가합니다.
- 히트맵 차트:
- 대시보드 구성 및 저장:
- 각 시각화를 Look 또는 Dashboard로 저장합니다.
- 대시보드에 여러 시각화(히트맵, 선 그래프, 코호트 차트 등)를 한데 모아 종합 리포트를 구성합니다.
5. 추가 팁
- Table Calculation:
Looker에서는 Table Calculation을 사용해 retention rate를 직접 계산할 수 있습니다. 예를 들어, day0 대비 각 day의 n_users 비율을 계산하는 식을 설정할 수 있습니다. - 필터 및 세그먼트:
Explore에서 특정 코호트(예: 특정 날짜 범위의 사용자를 선택)나 추가 필터(예: 디바이스 유형, 지역 등)를 적용하여 분석 범위를 세분화할 수 있습니다. - 공유 및 스케줄링:
만들어진 대시보드는 Looker 내에서 다른 팀원과 공유하거나 정기적으로 업데이트되도록 스케줄링할 수 있습니다.
이와 같이, CSV 파일을 BigQuery와 같은 데이터 웨어하우스에 업로드한 후 Looker와 연결하여 LookML을 통해 데이터를 모델링하고, Explore에서 시각화 옵션(히트맵, 선 그래프, 코호트 차트 등)을 활용함으로써 체계적으로 Retention 분석 대시보드를 구축할 수 있습니다.
CSV 파일 용량이 150MB를 초과할 때, Google Cloud Storage(GCS)를 이용하여 파일을 업로드하고 BigQuery로 로드하는 단계별 가이드입니다.
1. Google Cloud Storage에서 버킷 생성 및 CSV 파일 업로드
- Google Cloud Storage 페이지 접속
- Cloud Storage 페이지 링크: https://console.cloud.google.com/storage
- 버킷 생성
- 상단의 "버킷 만들기" 버튼을 클릭합니다.
- 버킷 이름: 전 세계에서 유일한 이름을 입력합니다. (예: my-cohort-csv-bucket)
- 저장소 위치: 데이터의 지리적 위치(예: 미국, 아시아 등)를 선택합니다.
- 스토리지 클래스: 일반적인 분석용이면 Standard를 선택합니다.
- 액세스 제어: 필요에 따라 퍼블릭 또는 프라이빗 액세스를 설정합니다.
- "만들기"를 클릭하여 버킷을 생성합니다.
- CSV 파일 업로드
- 방금 생성한 버킷을 클릭하여 버킷 내부로 이동합니다.
- "파일 업로드" 버튼을 클릭하여 CSV 파일을 선택하고 업로드합니다.
- 업로드가 완료되면 파일이 버킷 내에 나타납니다.
2. BigQuery에서 Cloud Storage의 CSV 파일을 이용하여 테이블 생성
- BigQuery 콘솔 접속
- BigQuery 페이지 링크: https://console.cloud.google.com/bigquery
- 새 테이블 생성
- 왼쪽 패널에서 원하는 프로젝트와 데이터셋을 선택한 후, 오른쪽 상단의 "테이블 만들기" 버튼을 클릭합니다.
- 소스에서 테이블 생성
- 소스 항목에서 "Google Cloud Storage"를 선택합니다.
- 파일 위치(URI):
- GCS에서 업로드한 CSV 파일의 URI를 입력합니다.
- 예시 형식:
-
gs://my01-11cohort-csv-01bucket/your_filename.csv
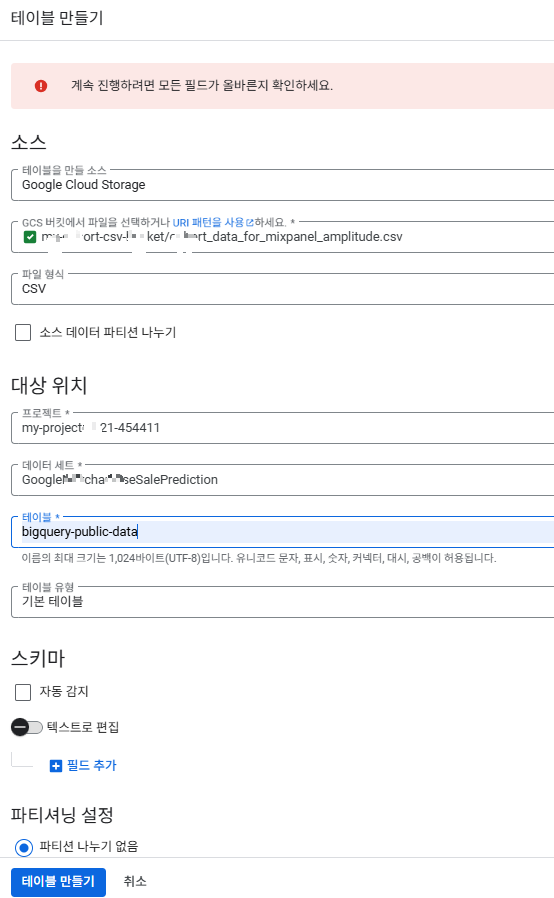
파일 형식: CSV로 선택합니다.
스키마 옵션:
스키마를 자동 감지(auto detect)하도록 선택하거나, 수동으로 각 컬럼의 이름과 데이터 타입을 입력합니다.
기타 옵션:
필요한 경우 파일의 구분자, 헤더 행 유무 등을 설정합니다.
4. 테이블 세부 정보 입력
- 프로젝트, 데이터셋, 테이블 이름: 원하는 이름과 위치를 설정합니다.
- 확인 후 "테이블 만들기" 버튼을 클릭하여 테이블을 생성합니다.
요약
- Cloud Storage에 CSV 파일 업로드:
- 새 버킷을 만들고 CSV 파일을 업로드합니다.
- BigQuery에서 GCS 파일을 소스로 사용하여 테이블 생성:
- BigQuery에서 테이블 생성 시 "Google Cloud Storage"를 소스로 선택하고, 파일 URI(gs://버킷명/파일명)를 입력하여 CSV 파일을 로드합니다.
이렇게 진행하면, 대용량 CSV 파일을 Cloud Storage에 올리고 BigQuery로 데이터를 로드하여 분석할 수 있다.
Google Cloud Storage에 올려둔 CSV 데이터를 Looker Studio(구 Data Studio)에서 불러와, Mixpanel/Amplitude 스타일의 코호트(리텐션) 시각화를 단계별로 만드는 방법입니다
CSV → BigQuery → Looker Studio
- **CSV 파일(대용량)**을 Google Cloud Storage(GCS)에 업로드
- BigQuery에서 GCS의 CSV를 이용해 테이블 생성
- Looker Studio에서 BigQuery 테이블을 데이터 소스로 연결
- Looker Studio의 차트 기능을 이용해 코호트(리텐션) 분석 시각화 구성
참고: 화면에 보이는 “Looker Studio”는 과거 “Google Data Studio”라는 이름으로 제공되던 Google의 대시보드/리포팅 툴이며, “Looker” (LookML을 사용하는 기존 솔루션)와는 별개의 제품입니다.
1. GCS → BigQuery로 CSV 테이블 생성 (이미 완료되었다 가정)
- Google Cloud Storage에 CSV를 업로드
- BigQuery 콘솔( https://console.cloud.google.com/bigquery )에서
- “테이블 만들기” → 소스: Google Cloud Storage → 업로드한 CSV 경로(gs://my-bucket/filename.csv) 입력
- 스키마(컬럼명, 데이터 타입) 자동 감지 or 직접 입력
- “테이블 만들기” 클릭
- BigQuery에 my_dataset.my_cohort_table 식으로 테이블 생성 완료
2. Looker Studio에서 BigQuery 테이블 연결
- Looker Studio 접속
- https://lookerstudio.google.com/
- 구글 계정으로 로그인
- 새 보고서 생성
- 상단 혹은 메인 화면에서 “보고서 만들기” 버튼 클릭
- 빈 캔버스(첨부하신 화면)에서 작업을 시작합니다.
- 데이터 소스 추가
- 좌측 상단 또는 우측 패널에 보이는 “데이터 소스 추가” 버튼을 클릭
- 팝업 창에서 BigQuery → 자신이 CSV를 넣어둔 프로젝트/데이터셋 → 테이블(예: my_cohort_table)을 선택
- "추가" 또는 "연결" 버튼으로 Looker Studio에 데이터 소스를 연결
3. Mixpanel / Amplitude 스타일의 Retention 분석을 위한 필드 설정
일반적으로 리텐션 분석에 필요한 필드는 다음과 같습니다.
- first_visit_date: 사용자(코호트)의 최초 방문(가입) 날짜
- days_since_first_visit: 첫 방문일 대비 몇 일이 지났는지
- n_users: 해당 시점에 남아있는 (또는 활성화된) 사용자 수
- (선택) retention_rate: n_users / (해당 코호트의 day0 사용자 수) * 100
A. 사용자 정의 필드 (필요시)
Looker Studio에서 “사용자 정의 필드” 기능을 통해, 예를 들어 retention_rate 같은 계산식을 만들 수 있습니다.
- 오른쪽 패널 - 필드 목록에서, 상단에 “사용자 정의 필드”(파란색 더하기 아이콘) 클릭
- Studio에서 조건부 집계가 조금 까다롭기 때문에, 데이터 구조에 따라 다른 식을 사용하거나, BigQuery 쿼리 레벨에서 계산해 두는 방법도 있습니다.
-
식예시
retention_rate = n_users / SUM(n_users) FILTER(조건: days_since_first_visit = 0)
만약 retention_rate 계산이 복잡하다면, BigQuery 쿼리 혹은 ETL 단계에서 미리 계산한 컬럼을 추가하는 편이 간편할 수 있습니다.
4. 차트 구성 (Mixpanel / Amplitude 유사 리텐션 시각화)
4-A. 선 그래프 (N-day Retention Curve)
- 보고서(대시보드) 편집 화면에서 “차트 추가” → “선 그래프” 선택
- 차원(Dimension) 설정
- “days_since_first_visit”를 x축(차원)으로 지정
- 측정값(Metric) 설정
- retention_rate (또는 n_users)를 y축으로 지정
- 필터/세그먼트
- 원한다면 “first_visit_date”를 특정 코호트(예: 특정 주간/월)로 필터링하거나, 여러 코호트를 비교하려면 차트 속성의 “계열 분할(Series Breakout)” 등을 사용
- 차트 옵션에서 표시 형식(라인, 포인트, 색상 등)을 조정해 Mixpanel의 리텐션 곡선처럼 시각화합니다.
4-B. 여러 코호트 동시 비교 (라인 차트)
- “차원”에 days_since_first_visit, “계열 분할(Series)”에 first_visit_date 추가
- 혹은 “분할 차원(브레이크다운)” 기능을 이용
- 측정값: retention_rate (또는 n_users)
- 차트 유형: “선 그래프”
- 이렇게 하면 Mixpanel/Amplitude처럼 각 코호트(최초 방문일)가 다른 색의 선으로 나타나, 서로 다른 코호트의 리텐션 추이를 한 번에 확인할 수 있습니다.
4-C. 코호트 히트맵 (Pivot Table 활용)
Looker Studio에서는 기본적으로 “Heatmap” 형태 차트가 없으므로, 피벗 테이블 + 조건부 색상(Conditional Formatting) 기능을 활용해 간이 히트맵을 만들 수 있습니다.
- “차트 추가” → “피벗 테이블” 선택
- 행(Row): first_visit_date (코호트)
- 열(Column): days_since_first_visit
- 값(Value): retention_rate(%) 또는 n_users
- 테이블 옵션에서 **“조건부 서식”**을 설정
- 예: 값이 높을수록 진한 파란색, 낮을수록 연한 회색 등
- 이를 통해 히트맵처럼 시각적으로 구분 가능
5. 대시보드 완성 및 공유
- 시각화 배치
- 선 그래프(코호트별 N-day Retention), 피벗 테이블(간이 히트맵), 바 차트(디바이스별 분포) 등을 한 화면에 구성
- 보고서 제목/설명 작성
- 공유 설정
- 우측 상단의 “공유” 버튼으로 팀원, 이해관계자와 링크를 공유하거나 보기 권한을 설정
- 정기 메일 전송 / PDF 내보내기
- Looker Studio에서 보고서 스케줄 전송(예: 매주 월요일), PDF로 다운로드 등도 가능합니다.
6. 마무리 팁
- 데이터 전처리(ETL) 추천
- Mixpanel/Amplitude처럼 자동 Retention 계산 기능이 없는 만큼, retention_rate, cohort_id, day0_user_count 같은 열을 BigQuery 레벨에서 미리 계산해 두면 스튜디오에서 편리하게 시각화할 수 있습니다.
- 추가 세그먼트
- 디바이스 유형, 국가, 캠페인별로 필터링해 리텐션 변화를 분석하면 Mixpanel/Amplitude처럼 상세 세그먼트 분석이 가능합니다.
- 여러 시트(Sheet) 구성
- 하나의 보고서 안에 여러 시트를 만들어 코호트 분석 / 퍼널 분석 / 디바이스 분석 등 주제별로 나눠 관리하기 좋습니다.
결론
- CSV → BigQuery로 테이블 생성
- Looker Studio에서 데이터 소스 연결
- 차트 유형(라인 그래프, 피벗 테이블)과 사용자 정의 필드(retention_rate 등)를 활용해
- N-day Retention 곡선 (Mixpanel/Amplitude 스타일)
- 코호트 히트맵(피벗+조건부 서식)
- 대시보드를 완성하고 공유/스케줄링
이 과정을 따르면, Mixpanel이나 Amplitude가 제공하는 Retention 시각화와 유사한 형태를 Looker Studio 내에서 쉽게 구현할 수 있다. 필요에 따라 BigQuery 스키마를 조금 더 정교하게 설계하거나, Looker Studio의 “사용자 정의 필드”를 적극 활용하여 원하는 지표를 만들수도 있다.
'데이터 분석가:Applied Data Analytics > 데이터 시각화' 카테고리의 다른 글
| Amplitude (앰플리튜드) 란? (1) | 2025.04.15 |
|---|---|
| 클라우드 슈퍼셋 시각화 - 이미지 바로 보이게 하기 (0) | 2025.04.11 |
| Sankey 차트를 LTV 시각화에 사용하는 이유 (0) | 2025.04.09 |
| Superset 클라우드 시각화 1st (0) | 2025.04.04 |
| 클라우드 Superset 시각화 (0) | 2025.04.03 |