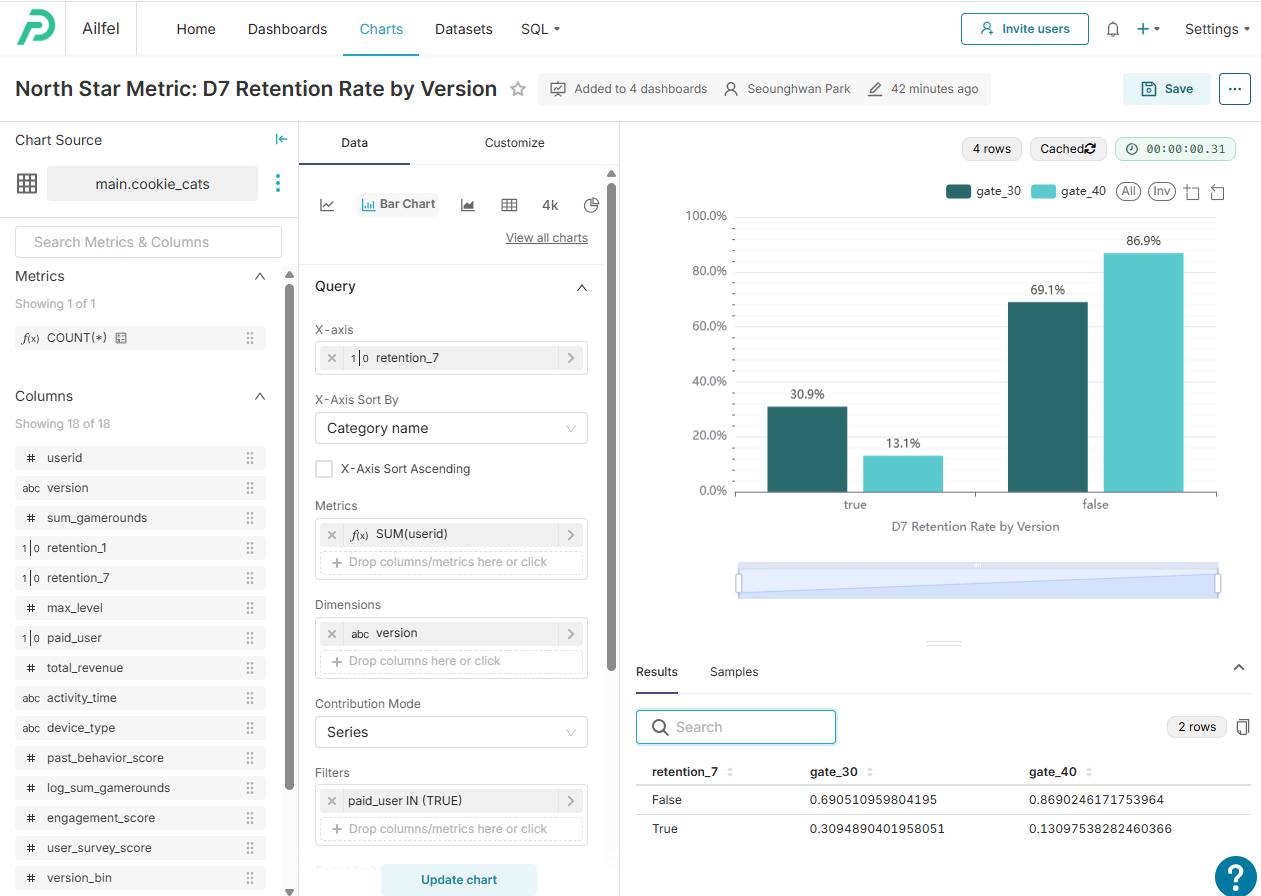
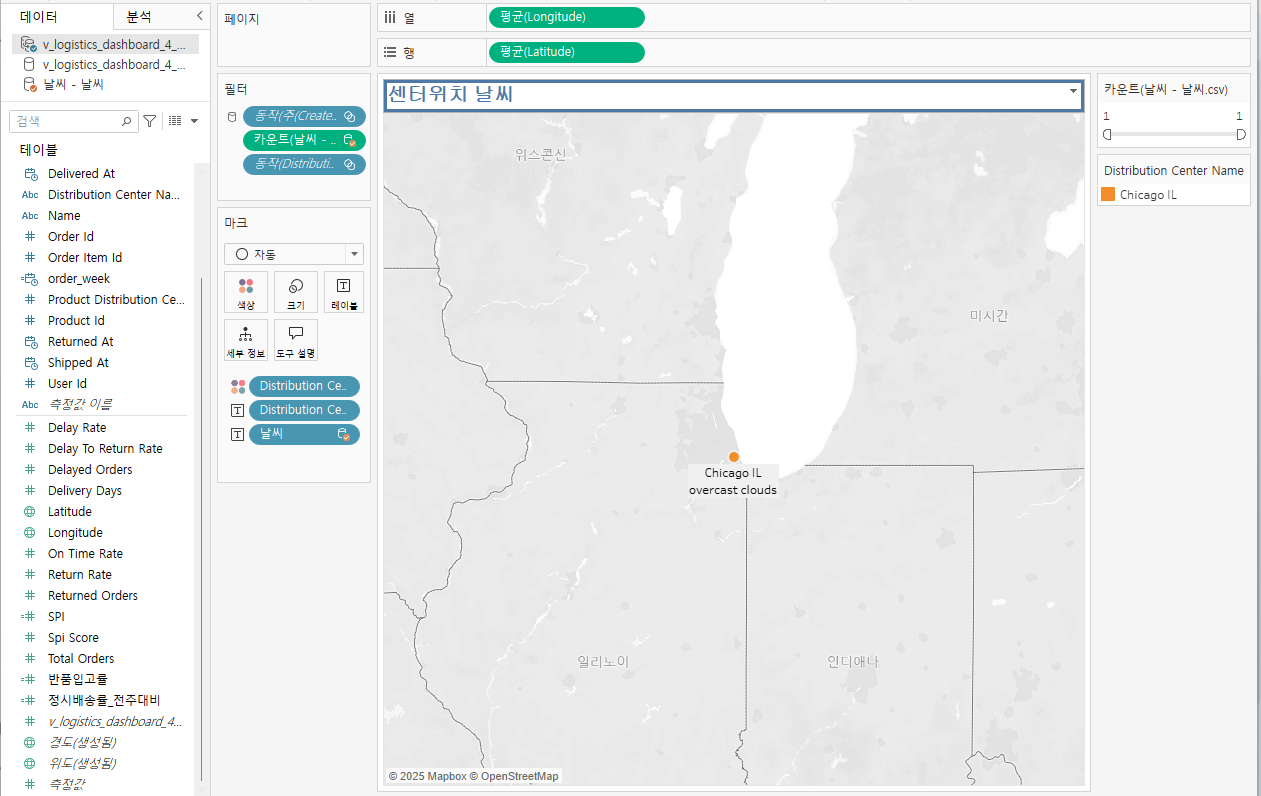
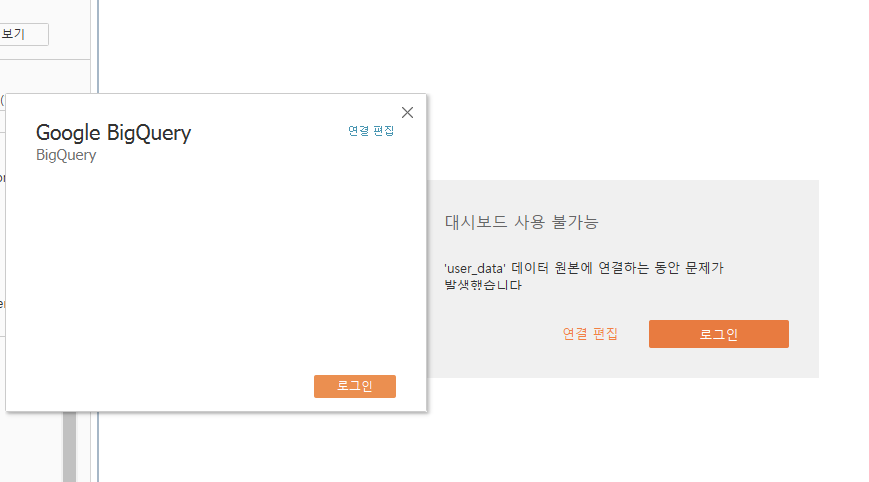
데이터 마이닝 개념과 기법종합적인 학문 및 기술 분야로서 데이터 마이닝의 특징을 소개하며, 정보 기술의 진화와 데이터 마이닝의 필요성, 그리고 응용 분야의 중요성에 대해 설명한다. 먼저, 데이터 마이닝을 위한 다양한 유형의 데이터 타입에 대해 알아보고, 데이터 마이닝 작업의 주요 유형과 마이닝 지식의 종류, 사용되는 기술의 종류, 그리고 분석 환경에 따라 활용되는 다양한 기법에 대해 설명한다.저자Jiawei Han, Pei Jian, Hanghang Tong출판에이콘출판출판일2025.01.311. AARRR (Acquisition, Activation, Retention, Revenue, Referral) AARRR은 데이터 분석을 통해 사용자 행동을 추적하고 개선하는 데 초점이 맞춰져 있습니다. 이에 ..