Superset 클라우드 호스팅 서비스
- Preset.io: Superset을 만든 회사에서 운영하는 공식 상업용 SaaS
- 사용자는 설치 없이 계정만 만들고 바로 협업 가능
- 무료 플랜 제공 (기능 제한 있음)
- 클라우드에서 Superset을 설치하면 협업에 최적화된 분석 환경 구성 가능
- Ubuntu 서버에 Superset을 설치해 공인 IP나 도메인을 통해 운영
- AWS EC2, Oracle Cloud, GCP 등이 설치 플랫폼으로 적합
- Nginx + HTTPS + 계정관리까지 구성하면 완전한 프로덕션 환경 가능
- Preset.io 계정 생성 및 사용법

가입한 후 한사람이 이메일 초대를 하면 서로 만날수 있다


서로의 작업공간을 만들수 있다.

Preset.io를 활용한 Superset 대시보드 구축 실습 가이드
Preset는 Apache Superset을 기반으로 한 클라우드 BI 플랫폼으로, 별도의 설치나 관리 없이도 Superset의 강력한 데이터 탐색·시각화 기능을 사용할 수 있다. 여기서는 Preset의 무료(Starter) 플랜을 사용하여 계정 생성부터 데이터 연결, 차트 작성, 대시보드 공유까지의 과정을 단계별로 살펴보겠습니다. 각 단계에서는 실제 화면 예시와 함께 따라 할 수 있도록 안내합니다.
1. Preset.io 회원가입 및 무료 워크스페이스 생성
① Preset 회원가입: Preset 웹사이트(preset.io)에 접속하여 “Try for Free” 등을 통해 회원가입을 진행합니다. 구글 계정으로 간편 로그인하거나 이메일로 가입할 수 있습니다. Preset은 최대 5명의 사용자까지 무료 팀을 구성할 수 있는 Starter 플랜을 제공하며, 가입 후 기본 워크스페이스를 생성하여 Superset 환경을 시작할 수 있다
슈퍼셋 & 프리셋
Apache Superset은 직관적이고 상호 작용하도록 설계된 강력한 오픈소스 데이터 탐색 및 시각화 플랫폼입니다. 데이터 전문가가 다양한 소스의 데이터를 빠르게 통합하고 분석하여 더 나은 의사 결정을 위한 통찰력 있는 대시보드와 차트를 만들 수 있습니다.
Preset 은 Apache Superset을 기반으로 구축된 클라우드 네이티브, 사용자 친화적 플랫폼입니다. 설치 및 유지 관리를 처리하지 않고도 Superset의 힘을 활용할 수 있는 향상된 기능과 관리 서비스를 제공합니다.
이 가이드에서는 Superset 또는 Preset을 사용하여 MotherDuck을 사용하는 방법에 대해 설명합니다.
슈퍼셋
설정
Superset을 로컬에서 시작하는 쉬운 방법은 docker-compose 구성을 사용하는 것입니다.
MotherDuck 에 데이터베이스 연결 추가
DuckDB 및 MotherDuck과 함께 작동하려면 추가 Python 패키지인 DuckDB SQLAlchemy 드라이버 duckdb-engine을 설치해야 합니다 .
여기의 단계에 따라 . 을 시작하기 전에 추가 패키지를 설치할 수 있습니다 docker-compose. 완료되면 이제 데이터베이스 연결을 추가할 수 있습니다.
- "설정"으로 이동하여 "데이터베이스 연결"을 클릭하세요.

- "+ 데이터베이스"를 클릭하세요

- 드롭다운에서 "DuckDB"를 선택하세요
DuckDB가 나열되지 않으면 . 설치에 오류가 있을 가능성이 큽니다 duckdb-engine. 이 추가 파이썬 패키지를 설치하려면 설치 단계를 검토하세요.
- 다음 패턴을 따르는 MotherDuck에 대한 SQLAlchemy URI를 입력하세요.
duckdb:///md:<my_database>?motherduck_token=<my_token>

데이터베이스 이름은 선택 사항 이므로 MotherDuck에 하나의 연결로 여러 데이터베이스를 쿼리할 수 있습니다.
마지막으로 "연결 테스트"를 클릭하고 "연결"을 클릭하여 토큰/연결이 유효한지 테스트할 수 있습니다.
이제 MotherDuck 데이터베이스를 Superset에서 사용할 수 있으며 대시보드를 만들어 볼 수 있습니다!
사전 설정
설정
사전 설정 계정은 무료 로 등록할 수 있습니다 (최대 5명의 사용자). 계정을 생성하면 작업 공간을 만들고 데이터 소스에 연결하라는 메시지가 표시됩니다.
MotherDuck 에 데이터베이스 연결 추가
사전 설정에서는 DuckDB SQLAlchemy 드라이버가 이미 설치되어 선택할 수 있으므로 추가 작업이 필요하지 않습니다.
Superset과 정확히 동일한 단계를 따르세요:
- "설정", "데이터베이스 연결"로 이동하여 데이터베이스 연결을 추가합니다.

- "+ 데이터베이스"를 클릭하세요
- 드롭다운에서 "DuckDB"를 선택하세요

- 다음 패턴을 따르는 MotherDuck에 대한 SQLAlchemy URI를 입력하세요.
duckdb:///md:<my_database>?motherduck_token=<my_token>

마지막으로 "연결 테스트"를 클릭하고 "연결"을 클릭하여 토큰/연결이 유효한지 테스트할 수 있습니다.
이제 MotherDuck 데이터베이스가 사전 설정으로 제공되므로 대시보드를 만들기 시작할 수 있습니다!
[참고 : (Superset & Preset | MotherDuck Docs)]
- 계정 활성화: 이메일 인증 등 가입 절차를 완료하면 Preset 관리 페이지(Preset Manager)에 로그인합니다.
② 워크스페이스 생성: Preset에 처음 로그인하면 워크스페이스(Workspace)를 만들라는 안내가 나타납니다. 워크스페이스란 관련된 데이터베이스 연결, 데이터셋, 차트, 대시보드를 한 곳에 묶어서 관리하는 작업 공간입니다 ([
Preset Cloud: An Open-Source BI Platform Built on Apache Superset
- Dynamic Data
](https://dynamicdata.com/blog/platform-preset/#:~:text=,of%20workspaces%20you%20can%20have)). Starter 플랜에서는 워크스페이스를 1개까지 생성할 수 있습니다(Professional 플랜에서는 추가 워크스페이스 생성 가능). 새 워크스페이스의 이름을 정하고 생성하면, 해당 워크스페이스가 Preset Manager의 목록에 나타납니다. 워크스페이스 생성 직후 **데이터 소스 연결**을 설정하는 단계로 넘어가며(나중에 설정 가능), 생성된 워크스페이스를 클릭하면 실제 Superset UI 화면으로 진입합니다 ([Superset & Preset | MotherDuck Docs](https://motherduck.com/docs/integrations/bi-tools/superset-preset/#:~:text=You%20can%20register%20a%20Preset,connect%20to%20your%20data%20source)).
2. Preset 기본 UI 구조 이해
워크스페이스에 들어오면 Apache Superset 인터페이스가 나타납니다. Preset은 최신 Superset 환경을 그대로 제공하므로, 상단 메뉴와 화면 구성이 Superset과 유사합니다. 주요 UI 구성 요소는 다음과 같습니다 ([
사전 설정에는 핵심이 되는 6가지 주요 UI가 포함되어 있습니다.
- 작업 공간 화면: 데이터베이스 연결, 데이터 세트, 차트 및 대시보드에서 상관 관계가 있는 데이터를 그룹화하는 방법입니다. 작업 공간은 단순히 자신과 다른 사람 간에 공유되는 모든 콘텐츠의 모음입니다. 가질 수 있는 작업 공간 수에는 제한이 있습니다.
- 홈페이지: 최근 패널, 대시보드 패널, 저장된 쿼리 패널, 차트 패널 등 일상적인 활동을 모두 수집합니다.
- 대시보드 화면: 여기에서는 필터 및 기타 기능과 함께 모든 차트를 레이아웃으로 고정할 수 있습니다.
- 차트: 시각화를 만드는 데 사용됩니다. Preset은 다양한 방식으로 데이터를 표시할 수 있는 매우 광범위한 시각화를 제공합니다.
- SQL Lab: 여기서 쿼리를 만들고, 저장된 쿼리에 액세스하고, 쿼리 기록을 검토할 수 있습니다.
- 데이터: 모든 데이터베이스와 데이터세트는 이 섹션에서 관리됩니다.



1. 사용자 유형
- 관리자: 팀(또는 조직)에 대한 액세스, 작업 공간에 대한 액세스를 관리하고 작업 공간에 있는 모든 정보에 액세스할 수 있습니다.
- 사용자: 초대를 통해 팀에 연결하고 제공된 권한에 따라 작업 공간에 액세스합니다.
역할-액세스 제어를 제공하는 관리자의 일반적인 워크플로는 다음과 같습니다.
- 이메일 초대를 통해 사용자를 팀에 초대합니다.
- 사용자에게 작업 공간 역할에 대한 액세스 권한을 부여합니다. 작업 공간에는 사용자에게 여러 역할이 있습니다. 지원팀에 문의하면 주문형으로 새 역할을 추가할 수 있습니다.
- 데이터 액세스 역할에 사용자 추가: 역할을 생성하고, 해당 역할에 사용자를 추가하고, 데이터베이스, 스키마, 테이블 및/또는 쿼리에 대한 권한을 부여할 수 있습니다.
- 마지막으로, 행 수준 보안으로 데이터 액세스를 제어합니다. 이 강력한 기능을 사용하면 선택한 데이터 세트나 테이블에서 특정 데이터를 쿼리하고 볼 수 있는 사람에 대한 세부적인 수준의 제어를 행사할 수 있습니다. 일반적으로 데이터 액세스 역할과 결합됩니다. 두 가지 필터 유형을 적용할 수 있습니다. 일반 필터는 사용자가 필터에서 참조하는 역할에 속하는 경우 쿼리에 where 절을 추가합니다. 기본 필터는 필터에 정의된 역할을 제외한 모든 쿼리에 필터를 적용하며 필터 그룹 내의 역할 수준 보안 필터가 적용되지 않는 경우 사용자가 볼 수 있는 내용을 정의하는 데 사용할 수 있습니다.
2. 데이터베이스 연결
Google BigQuery, Amazon Redshift, Snowflake, Databricks Hive, Azure Synapse, MySQL, PostgreSQL, Google Sheets 등 다양한 최신 데이터베이스를 지원합니다.
3. 알림 및 보고서
알림은 차트 또는 전체 대시보드의 스냅샷을 온디맨드로 제공하며 임계값 초과와 같은 이벤트가 발생하면 트리거됩니다. 이 이벤트는 카운트와 같은 고유한 값을 생성하는 SQL 쿼리로 정의됩니다. 알림은 이메일 및/또는 Slack을 통해 전달됩니다. 알림에서 차트 또는 대시보드의 시각적 스냅샷과 차트 또는 대시보드의 탐색 페이지로의 링크가 제공됩니다.
4. 지원 및 문서화
지식 기반: 도구의 기본 사항에 대한 온라인 문서와 비디오입니다.
사용자 코너: 다양한 주제를 다루는 전담 유튜브 채널입니다.
봇을 통한 도구의 지원: 저녁 식사 티켓을 열고, 회원 지원팀과 회의 일정을 잡고, 상담원과 24시간 온라인 채팅을 하세요.
5. 의미 계층
사전 설정에 추가하는 모든 데이터세트는 사용자 정의할 수 있습니다. 이러한 사용자 정의는 데이터세트 패널에 나타납니다. 필요에 따라 데이터를 그룹화한 다음(메트릭을 적용하는 경우) 차트를 만들 수 있습니다. 또한 데이터세트에 다음 항목을 추가할 수 있습니다.
메트릭: 집계된 행에서 사용되는 메트릭 로직을 정의하거나 행을 열로 피벗할 때 정의합니다. 메트릭의 이름, 레이블, 계산을 위한 SQL 표현식, 설명, 메트릭의 D3 형식, 경고 메시지, 인증(조직 또는 개인) 및 인증 세부 정보를 쉽게 수정할 수 있습니다. 메트릭에 경고 또는 인증이 있는 경우 데이터 세트를 탐색할 때 아이콘과 추가 정보가 나타납니다.
열: 표시할 열과 표시하지 않을 열, 별칭, 데이터 유형, 날짜 형식, 날짜인지, 필터링 가능한지, 차원인지 등의 여러 부울 설정을 선택할 수 있습니다.
계산된 열: 변환, 보강 또는 데이터 검증에 사용할 수 있으며, 열에 있는 것과 동일한 편집 가능한 필드와 SQL 표현식을 사용할 수 있습니다.




6. 차트
Preset에는 다양한 차트(50개 이상)가 제공됩니다. 다음은 추천 차트의 5가지 범주와 각 범주의 몇 가지 예에 대한 분석입니다.
- 시계열 차트: 선형 차트, 시계열 막대 차트, 시계열 표.
- 구성 차트: 막대형 차트, 원형 차트, 트리맵.
- 분포 차트: 히스토그램, 상자 그림, 수평선 차트.
- 관계형 차트: 피벗 테이블, 히트맵, 버블 차트.
- 지리공간 차트: 산점도, 호, 격자 및 다각형.
Preset에는 데이터세트 탐색기가 포함되어 있으므로 데이터를 쉽게 탐색하고 다양한 차트로 플레이하여 적절한 시각화를 만들 수 있습니다. 데이터를 탐색하고 여러 형식(JSON, CSV, 이미지)으로 내보낼 수 있는 완전하고 유연한 도구입니다.

일부 차트의 또 다른 흥미로운 기능은 데이터베이스에서 데이터를 검색한 후 사용할 수 있는 다양한 기능으로 구성된 고급 분석 입니다. 고급 분석의 주요 목표는 더 나은 시각화를 얻기 위해 데이터를 추가로 처리하는 것입니다.
- 롤링 윈도우: 평균, 합계, 표준 편차, 누적 합계 등의 통계적 값을 사용하여 값을 나타낼 수 있습니다.
- 시간 비교: 실제 값, 절대 차이, 백분율 변화 또는 비율을 활용하여 시간 이동을 통해 동일한 데이터 시리즈를 비교합니다.
- Python 함수: 데이터베이스에서 가져온 데이터는 pandas DataFrame에 저장되어 다음과 같은 시나리오에서 사용할 수 있는 분석 기능을 수행합니다. 고급 분석은 지원되지 않는 경우, 데이터가 누락된 경우, 기간을 기준으로 데이터를 그룹화하고 방법을 기준으로 값을 표시하는 경우입니다.
7. 대시보드
대시보드는 관련 차트를 그룹화하는 방법이며, 동일한 차트를 여러 대시보드에 추가할 수 있습니다. 대시보드 화면은 행과 열로 구성된 그리드 레이아웃으로 구성되며, 차트를 위한 공간을 만들기 위해 행이나 열을 모호하게 추가할 수 있습니다.
대시보드 내에서 필터 시각화 유형을 사용하면 사용자가 대시보드의 모든 차트에서 데이터를 직접 필터링할 수 있습니다. 필터에는 영향을 받을 차트를 사용자 정의하는 기능이 있습니다. 데이터를 필터링하는 또 다른 방법은 사용하기 쉬운 직관적인 인터페이스가 있는 Preset의 대시보드 필터를 사용하는 것입니다. 모든 대시보드에서 필터 사이드바를 확장하여 대시보드 내의 모든 차트에 다양한 필터를 빠르게 적용할 수 있습니다.
대시보드 콘텐츠는 탐색 및 프레젠테이션 목적으로 여러 탭으로 구성할 수 있으며, 이를 통해 차트를 의미 있게 배열할 수 있는 유연성을 제공합니다.
대시보드에 마크다운 구성요소를 추가하면 마크다운, CSS 및/또는 HTML을 사용하여 해당 구성요소를 사용자 정의할 수 있습니다.
CSS를 사용하면 이미지를 삽입하고 대시보드의 모양과 느낌을 완전히 바꿀 수 있습니다.
8. SQL 랩
SQL Lab은 사용자가 사전 설정 환경에서 SQL 사용의 모든 측면을 관리할 수 있는 작업 공간입니다. 여러 쿼리를 동시에 작업할 수 있는 멀티탭 환경을 제공하는 유용한 도구입니다. 데이터베이스를 탐색하고, 오랫동안 실행 중인 SQL 쿼리, 쿼리의 기록 로그를 지원하고, Jinja 템플릿 언어를 사용하여 SQL 코드에서 매크로를 사용할 수 있는 템플릿을 지원할 수 있습니다.
SQL Lab은 SQL 편집기, 저장된 쿼리, 쿼리 기록이라는 세 가지 도구로 구성되어 있습니다.
SQL Lab은 또한 Python 프로그래밍 언어용 웹 템플릿 엔진인 Jinja Framework를 통해 템플릿화(프로그래밍 기능)를 지원합니다. SQL 생성 측면에서 제공되는 유연성 외에도 템플릿화는 주로 사전 설정 필터 기능의 성능을 높이는 데 사용됩니다. 예를 들어 현재 로그인한 사용자의 데이터를 필터링하거나, 대시보드 URL에서 동적으로 필터를 변경하거나, 필드에서 나오는 포맷된 데이터를 처리하거나, 대시보드를 개인화해야 하는 경우입니다.

9. 사전 설정된 임베디드 SDK
간단한 배포를 통해, 우리는 외부 애플리케이션에 생성된 대시보드를 통합하여 사용자 경험을 풍부하게 하고, 대화형 분석 경험으로 전환할 수 있습니다. 인프라를 보호하기 위해, Preset은 유연한 액세스 제어를 제공하는 다양한 보안 기능을 제공합니다.
10. 일반 제한 사항
사전 설정은 Data Exploration 계층 내의 여러 테이블에서 시각화를 만드는 것을 허용하지 않습니다.
SQL을 사용하지 않고도 의미론을 설계할 수 있지만, 일부 정의에는 SQL에 대한 기본 지식이 필요합니다. 일반적인 기술 설정을 하고 SQL을 사용하지 않는 사용자가 모델을 확장하고 차트와 대시보드를 만들 수 있도록 하는 것이 유익할 것입니다.
NoSQL 데이터 소스를 지원하지 않습니다. 데이터베이스에 스테이징 영역을 두고 테이블을 가져온 다음 해당 테이블을 조작하여 모델을 만들면 이러한 제한을 쉽게 극복할 수 있습니다.
버전 제어는 Superset이 대시보드의 구성 요소를 전용 데이터베이스에 별도로 저장하기 때문에 명시적인 기능이 아닙니다. 즉, Preset은 사용자가 대시보드를 YAML 구성으로 버전 관리하고 API를 통해 인스턴스 간에 이동할 수 있는 다가올 기능을 티저로 공개했습니다.
대시보드와 차트는 드릴다운 기능과 함께 사용할 수 없습니다. Preset에서 이 기능을 개발 중이며 향후 버전에서 사용할 수 있을 것이라고 합니다.
데이터 소스나 차트를 보거나 수정하는 경우 명확한 지표나 레이블이 없습니다. 서로 비슷하지만 다른 목적이 있는 다른 작업 공간에 있을 때도 같은 일이 발생합니다.
예약된 보고서는 필터를 지원하지 않습니다. 기본 필터로 보고서를 보내거나 상황에 따라 다른 보고서를 만들게 됩니다. 또한 CSV 또는 Excel 파일과 같은 첨부 파일도 허용되지 않습니다. 수신하는 이메일/슬랙 메시지는 이미지와 대시보드 링크일 뿐이므로 모든 수신자는 Preset에서 계정을 만들어야 합니다.
마지막으로, Python이나 R과 같은 프로그래밍 언어는 추가적이고 유연한 분석을 위해 지원되지 않습니다. 그러나 특정 유형의 차트를 만들 때 사용할 수 있는 일부 제한된 Python 분석 함수를 제공합니다.
이것으로 Preset에 대한 평가를 마칩니다. 대부분의 BI 플랫폼이 빠르게 성장하고 있기 때문에 조만간 다시 평가해야 할 것으로 보입니다.
곧 더 많은 BI 플랫폼 리뷰가 공개될 예정이니 기대하세요. 이상까지가 해당
[참고 : https://dynamicdata.com/blog/platform-preset/#:~:text=,are%20managed%20in%20this%20section)).]
- 홈 화면(Home): 최근에 본 대시보드나 차트, SQL 쿼리 등을 한눈에 보여주는 대시보드입니다. 로그인 직후 표시되며, 최근 작업한 항목(Recents), 대시보드, 차트, 저장된 쿼리 등이 패널 형태로 나열됩니다.
- 데이터(Data) 섹션: 데이터베이스와 데이터셋을 관리하는 영역입니다. 상단 메뉴의 Data를 클릭하면 Databases(데이터베이스 연결)와 Datasets(데이터셋 목록), 그리고 (SQL Lab에서 작성한) Saved Queries 탭을 볼 수 있습니다. 여기서 새로운 데이터베이스를 연결하거나 데이터셋을 등록할 수 있다.
- 차트(Charts): 차트 리스트 및 차트 생성 화면입니다. 현재 워크스페이스에 저장된 모든 차트가 표시되며, + Chart 버튼을 통해 새 차트를 만들 수 있습니다. 차트 생성 시에는 데이터셋과 시각화 타입을 선택한 후, 차트 설정(필드, 집계 등)을 구성하게 됩니다 ([
- Preset Cloud: An Open-Source BI Platform Built on Apache Superset - Dynamic Data ](https://dynamicdata.com/blog/platform-preset/#:~:text=,are%20managed%20in%20this%20section)).
- 대시보드(Dashboards): 여러 차트를 모아 하나의 화면으로 구성한 대시보드 리스트 화면입니다. 워크스페이스의 모든 대시보드가 나열되며, + Dashboard 버튼 (또는 차트 저장 시 대시보드 생성 옵션)을 통해 새로운 대시보드를 만들 수 있다. 대시보드 편집 모드에서는 차트 배치, 크기 조절, 필터 추가 등의 레이아웃 편집이 가능합니다 ([
- Preset Cloud: An Open-Source BI Platform Built on Apache Superset - Dynamic Data ](https://dynamicdata.com/blog/platform-preset/#:~:text=,and%20review%20the%20query%20history)).
- SQL Lab: SQL 편집기 기능으로, 데이터베이스에 직접 쿼리를 작성하고 실행해 볼 수 있는 공간입니다. 작성한 쿼리는 저장(Save)하여 나중에 재사용할 수 있으며, 팀원들과 Saved Queries를 통해 공유할 수도 있다 ([
- Preset Cloud: An Open-Source BI Platform Built on Apache Superset - Dynamic Data ](https://dynamicdata.com/blog/platform-preset/#:~:text=,are%20managed%20in%20this%20section)). **SQL Lab**은 SQL에 익숙한 사용자를 위한 강력한 쿼리 분석 도구이며, 작성된 쿼리를 기반으로 새로운 **데이터셋**을 생성할 수도 있다.
以上がPreset/Supersetの基本的なUI構造です (UI labels are in English on Preset). 이제 실제로 데이터를 연결하고 차트와 대시보드를 만들어 보겠습니다.
3. 데이터셋 추가: CSV 업로드 및 데이터베이스 연결
워크스페이스를 만들었다면, 차트를 생성하기 위해 먼저 데이터셋(Dataset)을 등록해야 합니다. 데이터셋은 차트에서 사용할 데이터 테이블 또는 뷰를 가리키며, CSV 파일을 직접 업로드하거나 외부 데이터베이스를 연결한 후 해당 테이블을 등록하는 방식으로 추가할 수 있습니다. Preset의 Starter 워크스페이스에는 기본적으로 예제용 SQLite 데이터베이스(examples)와 CSV 업로드용 데이터베이스(File Uploads)가 미리 연결되어 있다 (Preset Databases - Preset Docs). 따라서 사용자는 자체 데이터를 업로드하거나 별도의 DB를 연결하여 데이터셋을 구성하면 됩니다. 여기서는 CSV 파일 업로드 방법과 외부 데이터베ース 연결 방법을 각각 설명합니다.
- ① CSV 파일 업로드를 통한 데이터셋 생성:
Preset/Superset에서는 CSV 또는 Excel 파일을 데이터베이스에 업로드하여 새로운 테이블로 추가할 수 있다. 업로드된 CSV는 Preset이 제공하는 내부 데이터베이스(기본 File Uploads DB)에 저장되고, 자동으로 데이터셋으로 등록됩니다. 업로드 절차는 다음과 같습니다:- 화면 오른쪽 상단의 + 아이콘을 클릭하고 Data -> Upload CSV to database 메뉴를 선택합니다 (Using Google Sheets and CSV files - Preset Docs). (또는 상단 메뉴에서 Settings -> Data -> Database Connections로 이동한 뒤, Upload file to database -> Upload CSV를 클릭해도 됩니다 (Exploring Data in Superset | Superset).)
- 파일 선택 창이 나타나면 CSV 파일을 선택합니다. CSV 파일의 첫 행에 컬럼명이 포함되어 있어야 합니다.
- CSV를 어떤 데이터베이스에 저장할지 선택합니다. 기본적으로 examples나 File Uploads 등의 DB를 선택할 수 있는데, File Uploads를 선택하면 Preset이 내부적으로 마련한 데이터베이스에 테이블이 생성됩니다. 스키마(Schema)는 보통 public(기본값)을 사용합니다.
- **테이블 이름(Table Name)**을 입력합니다. 해당 이름으로 데이터베ース에 테이블이 생성됩니다 (Exploring Data in Superset | Superset). (동일 이름의 테이블이 이미 있으면 덮어쓸지 여부를 묻습니다.)
- 필요에 따라 고급 설정을 조정합니다. (예: 날짜 컬럼이 있는 경우 "Columns to be parsed as dates"에 컬럼명을 지정하면 날짜형으로 파싱됨)
- 설정을 마쳤으면 Upload 버튼을 눌러 업로드를 시작합니다. 업로드가 완료되면 “테이블이 성공적으로 추가되었다”는 확인 메시지가 나타납니다.
- ② 데이터베ース 연결을 통한 데이터셋 생성:
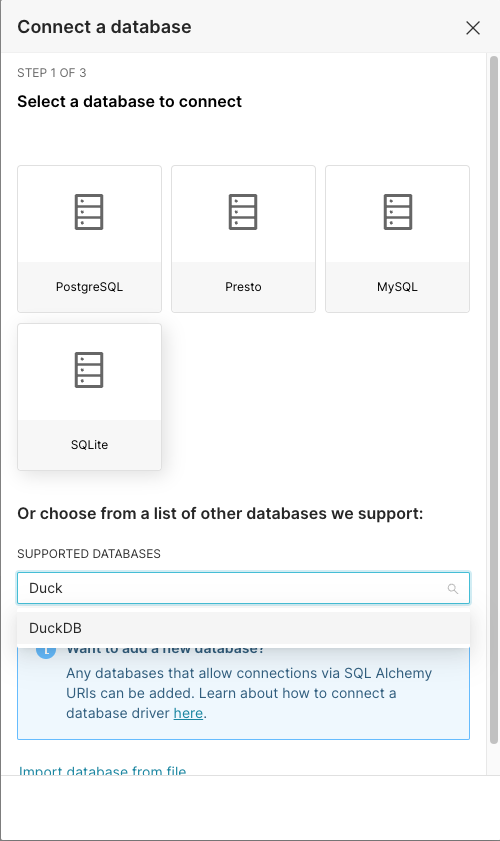
이미 사용 중인 **외부 데이터베ース(MySQL, PostgreSQL, BigQuery 등)**가 있다면, 해당 DB를 Preset에 연결하여 그 안의 테이블들을 데이터셋으로 등록할 수 있다. Preset Starter 플랜에서도 다양한 데이터베이스를 지원하며, SQLAlchemy 연결 문자열을 통해 추가로 등록할 수도 있습니다. 데이터베이스 연결 절차는 다음과 같다:- 상단 메뉴에서 Data -> Databases를 선택하여 데이터베이스 연결 관리 화면으로 이동합니다. 화면 우측 상단의 + DATABASE 버튼을 클릭하면 Connect a database라는 창이 나타납니다.
-
- (preset.io) 그림: Preset의 데이터베이스 연결 추가 화면. BigQuery, PostgreSQL, Snowflake, MySQL 등 다양한 DB를 선택해 연결할 수 있다.
- 데이터베이스 종류 선택: 연결 마법사 창에서 Preset이 기본 제공하는 여러 종류의 데이터베이스 아이콘이 표시됩니다. 예를 들어 PostgreSQL을 클릭하면 해당 DB에 필요한 정보를 입력하는 단계로 진행됩니다. 만약 목록에 없는 DB라도 SQLAlchemy 연결 URI가 있다면 하단의 드롭다운에서 “Choose a database…”를 통해 추가 지원 가능합니다. (단, SSH 터널 등이 필요한 경우는 상위 플랜이 필요할 수 있다.)
- 접속 정보 입력: 선택한 DB 유형에 따라 호스트주소, 포트, 데이터베이스명, 사용자명/비밀번호 등 필요한 정보를 입력합니다. 예를 들어 PostgreSQL의 경우 호스트(URL), 포트(기본 5432), 데이터베이스 이름, 사용자 이름과 암호를 입력하고 **“Test Connection”**으로 연결 확인을 한 뒤 Connect를 클릭합니다. (BigQuery나 Google Sheets의 경우 OAuth 또는 API 키 등의 인증이 필요할 수 있다.)
- 데이터베이스 등록 확인: 연결에 성공하면 Databases 목록에 새 DB가 추가됩니다. 이제 이 데이터베이스 내의 테이블을 데이터셋(Dataset)으로 등록해야 차트에서 사용할 수 있습니다. 상단 메뉴 Data -> Datasets으로 이동하여 + Dataset 버튼을 클릭합니다. 나타나는 패널에서 방금 연결한 데이터베이스와 해당 Schema를 선택하면, 그 아래에 해당 DB의 테이블 목록이 나타납니다 (preset.io). 여기서 시각화에 사용할 특정 테이블이나 뷰를 선택하고 Add를 누르면 해당 테이블이 데이터셋으로 추가됩니다.
- 데이터셋 확인: Datasets 목록에서 추가된 데이터셋이 보이는지 확인합니다. 데이터셋 이름은 기본적으로 데이터베이스이름.스키마.테이블명 형태로 표시됩니다 (필요하면 우측 … -> Edit 메뉴에서 표시 이름 등을 편집할 수 있습니다). 이제 이 데이터셋을 클릭하여 차트 생성 화면으로 이동할 수 있다.
※ 참고: Preset의 예제 DB(examples)에는 기본적으로 몇 가지 샘플 테이블이 포함되어 있습니다. 처음 접속 시 샘플 대시보드나 차트를 확인해보고 싶다면, Dashboards 메뉴에서 예제 대시보드가 있는지 찾아보세요. 만약 없다면 examples DB에 있는 birth_names, world_bank_health_population 등의 테이블을 데이터셋으로 등록하여 실습해 볼 수 있다.
4. 차트 생성과 대시보드 구축
데이터셋을 준비했으면 이제 해당 데이터를 시각화하는 **차트(chart)**를 만들고 이를 **대시보드(dashboard)**에 구성해보겠습니다. 차트 생성과 대시보드 추가 과정은 다음과 같다:
① 차트 생성 (Explore): Preset/Superset에서 차트를 만들려면 우선 사용할 데이터셋을 선택해야 합니다. 방법은 두 가지가 있다. (A) Datasets 화면에서 원하는 데이터셋 행을 클릭하면 곧바로 차트 편집 화면인 Explore로 이동합니다 (Exploring Data in Superset | Superset). (B) 혹은 Charts 화면에서 + Chart 버튼을 누르면 “어떤 데이터셋으로 차트를 만들 것인지” 선택하는 창이 뜹니다. 여기에서 데이터셋과 차트 종류(예: 막대 차트, 라인 차트 등)를 선택하여 차트 작성 화면으로 들어갈 수도 있다.
차트 편집 화면(Explore)에서는 좌측에 데이터 패널(데이터셋의 컬럼 및 필드 선택 영역)이, 우측에 시각화 미리보기 패널이 나타납니다. 화면 상단에서 **차트 유형(Visualization Type)**을 변경할 수 있으며, 기본적으로 방금 선택한 차트 유형이 설정되어 있습니다. 이제 예시로 간단한 막대 차트를 만들어 보겠습니다:
- X축, Y축 등 설정: 좌측 패널에서 차트에 사용할 컬럼을 선택합니다. 예를 들어 시간에 따른 사용자 수를 그리는 **시계열 막대 차트(Time-series Bar Chart)**의 경우, X축에 해당하는 **시간 컬럼(Time Column)**과 Y축 값에 해당하는 행 개수(count) 또는 합계(sum) 등의 **메트릭(Metric)**을 지정해야 합니다. Time Column에는 데이터셋의 날짜/시간 컬럼을, Metrics에는 합계낼 숫자 컬럼을 드래그하여 놓으면 됩니다. 또한 Group By나 **필터(Filter)**가 필요한 경우 해당 필드를 설정합니다. 설정 옵션들은 차트 유형에 따라 좌측 패널에 동적으로 표시됩니다.
- 차트 미리보기: 필요한 필드를 설정한 뒤 상단의 Run 또는 Update Chart 버튼을 클릭하면 쿼리가 실행되어 우측 패널에 차트 미리보기가 나타납니다. 예를 들어 일자별 최대값 차트를 그렸다면, X축에 날짜별 데이터 포인트가, Y축에 계산된 값이 그래프로 표시됩니다. 쿼리 결과 행 수나 실행 시간도 함께 표시됩니다. 만약 데이터가 의도한 대로 나오지 않으면 좌측 설정을 조정하고 다시 업데이트합니다. (필요 시 우측 ... 메뉴에서 실행된 SQL 쿼리를 확인할 수도 있다.)
- 차트 저장: 차트 구성이 완료되면 화면 우측 상단의 Save 버튼을 눌러 차트를 저장합니다. 저장 창에서 차트의 이름을 입력하고, 이 차트를 추가할 대시보드를 선택하거나 새 대시보드 이름을 입력할 수 있다. 처음 만든 차트이므로 “Add to Dashboard” 필드에 새 대시보드 이름을 입력해 봅시다. 예를 들어 My First Dashboard라고 입력하면, 저장과 동시에 해당 이름의 새로운 대시보드가 생성되고 지금 만든 차트가 그 대시보드에 추가됩니다 (preset.io).저장 창에서 “Save & Go to Dashboard” 버튼을 누르면, 방금 만든 대시보드 화면으로 바로 이동합니다. (일반 Save를 누른 경우, Dashboards 메뉴에서 해당 이름의 대시보드를 찾아 열면 됩니다.)
- (preset.io) 그림: 차트를 저장하면서 대시보드에 추가하는 화면. 새로운 대시보드 이름을 지정하여 차트와 함께 생성할 수 있다.
② 대시보드 구성: 새로 열린 대시보드는 기본적으로 방금 추가한 차트 한 개만 포함한 상태입니다. Edit Dashboard 모드로 들어가 레이아웃을 조정하고 추가 설명을 넣어보겠습니다. 대시보드 화면 우측 상단의 편집(Edit) 버튼을 클릭하면 대시보드 편집 모드가 활성화됩니다. 이제 다음을 수행할 수 있다:
- 차트 크기 및 위치 조정: 대시보드 캔버스에서 차트 카드의 모서리를 드래그하여 크기를 조절하거나, 드래그앤드롭으로 위치를 이동시킬 수 있습니다. 여러 차트를 배치할 때 적절한 레이아웃으로 정렬하세요.
- 차트 추가: 편집 모드에서 화면 상단의 + 아이콘을 클릭하면, 현재 워크스페이스에 존재하는 차트 목록이 나타납니다. 여기서 대시보드에 추가하고 싶은 기존 차트를 선택하면 새로운 패널로 해당 차트가 추가됩니다. (또는 Add Chart 버튼을 통해 추가.)
- 텍스트 또는 필터 추가: 대시보드에는 차트 이외에도 설명용 텍스트를 넣거나, 필터 구성 요소를 추가하여 대시보드 내 여러 차트를 동시에 필터링할 수 있습니다. Add Component 메뉴를 통해 Markdown 텍스트 블록이나 Filter Box 등을 추가해보세요. 예를 들어 “매출 대시보드”와 같은 제목이나 설명을 Markdown으로 작성해 상단에 배치할 수 있다.
- 저장: 편집을 완료하면 Save 버튼을 눌러 대시보드 레이아웃 변경사항을 저장합니다. 이제 대시보드를 뷰 모드로 돌아와서 전체 화면으로 차트와 구성 요소들을 살펴볼 수 있다.
대시보드가 완성되었습니다! 필요에 따라 언제든 Edit 모드로 돌아가 차트를 추가하거나 레이아웃을 변경하고 다시 저장할 수 있습니다.
5. 대시보드 공유 및 협업 기능
Preset Starter 플랜에서는 팀원들과 함께 대시보드를 만들고 공유할 수 있다. 협업(collaboration)을 위해 최대 5명까지 한 워크스페이스에 사용자를 추가할 수 있으며, 팀원 모두가 관리자 권한으로 모든 콘텐츠에 접근 가능 (preset.io) (Free Tier Limits - Preset Docs). Preset에서의 공유 및 협업 방법은 다음과 같다:
- 팀원 초대: 워크스페이스에 다른 사용자를 추가하려면, 화면 상단의 Invite Users 버튼을 클릭하거나 Preset Manager에서 Manage Team 옵션을 사용합니다. 초대하려는 사용자의 이메일을 입력하면 해당 주소로 초대장이 발송됩니다. 초대를 받은 사용자는 Preset 계정을 만들어 팀에 합류하게 되며, 곧바로 해당 워크스페이스의 대시보드와 차트, 데이터에 접근할 수 있다. (Starter 플랜에서는 추가된 모든 사용자가 Team Administrator로 간주되어 동일한 편집 권한을 갖습니다.)
- 대시보드 공유: 팀원이 워크스페이스에 추가되었다면, 대시보드 URL을 직접 공유하는 것만으로도 대시보드를 함께 볼 수 있습니다. 대시보드 화면 우측 상단의 Share 아이콘 (화살표 모양) 버튼을 눌러 URL을 복사(copy) 할 수 있습니다. 이 URL을 팀원에게 전달하면, 팀원은 해당 링크로 대시보드에 접속하여 내용을 볼 수 있습니다. (Preset 대시보드 링크는 기본적으로 워크스페이스 내에서만 접근 가능하므로, 로그인하지 않은 외부인은 볼 수 없다.)
- 편집 및 협업: 동일 워크스페이스에 있는 팀원이라면 누구나 차트 편집, 대시보드 레이아웃 변경 등의 작업을 수행하고 저장할 수 있습니다. 예를 들어 한 사용자가 차트를 수정해 저장하면 그 차트가 속한 대시보드에도 변경사항이 반영됩니다. 여러 사람이 동시에 대시보드를 편집할 경우 마지막 저장자가 우선하므로, 편집 시에는 한 명씩 순차적으로 작업하는 것이 좋다. SQL Lab의 Saved Queries나 Datasets도 팀 전원이 공유하므로, 한 사람이 저장한 쿼리나 등록한 데이터셋을 다른 팀원이 활용할 수도 있다.
- 공개 공유 및 임베드: 대시보드를 비로그인 사용자에게 공개하거나 웹 애플리케이션에 임베드(embed)하는 기능은 Preset의 상위 플랜에서 지원됩니다. Starter 플랜에서는 팀 초대를 통한 내부 공유만 가능하며, 외부 공개 링크를 생성할 수는 없습니다. 대신 대시보드 화면을 이미지로 내보내거나(캡처), PDF로 다운로드하는 기능은 브라우저 인쇄 등을 통해 수동으로 가능합니다. 조직 내 폭넓은 공유가 필요하다면 Professional 플랜으로 업그레이드하여 뷰어(읽기 전용 사용자)를 추가하거나 임베드 기능을 활용할 수 있다 (preset.io).
6. Preset 무료 플랜(Starter)의 주요 제한 사항
마지막으로 Preset Starter (무료) 플랜의 제한 사항을 정리합니다. 무료 플랜은 소규모 팀이 Superset을 손쉽게 활용해보도록 설계되어 있으며, 핵심 기능은 대부분 포함하지만 몇 가지 제약이 있다:
- 사용자 수 제한: 한 워크스페이스 당 최대 5명까지 사용자 초대가 가능합니다 (preset.io) (preset.io). 소규모 팀 협업 용도로 적합하며, 5명을 초과하는 인원이 참여하려면 상위 플랜으로 업그레이드해야 합니다.
- 워크스페이스 수 제한: 워크스페이스 1개만 생성할 수 있습니다 (preset.io). 프로젝트별로 분리된 여러 개의 Superset 공간이 필요한 경우 Starter 플랜에서는 어렵고, Professional 플랜(최대 3개 워크스페이스) 이상을 고려해야 합니다.
- 권한 관리: 세분화된 RBAC(Role-Based Access Control) 기능이 제공되지 않습니다. 무료 플랜에서는 초대한 모든 사용자가 관리자 권한을 가지며 워크스페이스 내 모든 객체에 접근/편집이 가능합니다 (Free Tier Limits - Preset Docs). 따라서 뷰어 전용 권한이나 편집 제한 등을 설정할 수 없고, 세밀한 권한 관리는 불가능합니다.
- 스케줄링 기능: 이메일/Slack 리포트나 알림(Alerts) 기능을 사용할 수 없습니다 (preset.io). 예를 들어 특정 대시보드를 정기적으로 이메일로 구독 받거나, 임계치 도달 시 Slack 알림을 보내는 자동화 기능은 Professional 플랜부터 지원됩니다. Starter 플랜에서는 대시보드를 수동으로 확인해야 하며, 필요 시 상위 플랜 업그레이드로 해당 기능을 활용할 수 있다.
- 기술 지원: Preset Docs 등의 문서와 튜토리얼은 자유롭게 이용 가능하지만, 전담 지원(Support)은 제한적입니다. 긴급한 이슈 대응이나 SLA 수준의 지원은 엔터프라이즈 플랜에 포함되며, 무료 이용자는 커뮤니티 포럼이나 자체 해결에 의존해야 합니다.
- 기타 제한: 엔터프라이즈 기능(SSO 지원, 감사 로그, 다중 리전 선택, 전용 VPC 등)은 무료 플랜에 포함되지 않습니다. 또한 대시보드 임베디드 공유의 경우 Professional 이상에서 별도 애드온으로 제공되는 기능입니다 (preset.io). 다만 시각화 차트 종류(40여 종), 차트/대시보드 개수에는 제한이 없으며 (preset.io), Superset의 거의 모든 표준 기능을 제약 없이 사용할 수 있습니다. 즉, 소규모 팀이 사용하기에는 무료 플랜의 기능으로도 충분하며 필요 시 언제든 업그레이드할 수 있다.
이상으로 Preset의 무료 플랜을 활용한 Superset 대시보드 구축 방법을 살펴보았습니다.
요약하면, Preset.io에 가입하여 워크스페이스를 만들고 → 데이터소스를 연결하거나 CSV를 업로드하여 데이터셋을 생성하고 → 차트를 만든 뒤 대시보드에 추가 및 편집하고 → 팀원과 공유하는 흐름입니다. Preset을 통해 설치/서버 관리 부담 없이도 손쉽게 Superset의 강력한 데이터 시각화 기능을 활용해보세요. 필요한 경우 Preset 공식 문서와 튜토리얼, 예제 대시보드를 참고하면 더 많은 활용 팁을 얻을 수 있다.
여러명이 한팀으로 접속한 상태 내작업공간을 아래 처럼 만들었다. Steven

내 작업공간 WorkSpace로 들어온 모

'데이터 분석가:Applied Data Analytics > 데이터 시각화' 카테고리의 다른 글
| Sankey 차트를 LTV 시각화에 사용하는 이유 (0) | 2025.04.09 |
|---|---|
| Superset 클라우드 시각화 2nd (0) | 2025.04.04 |
| Superset 클라우드 시각화 1st (0) | 2025.04.04 |
| 클라우드 Superset 시각화 (0) | 2025.04.03 |
| Superset 설치 (0) | 2025.04.02 |