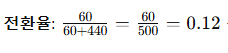1. 오차(Error)실제값과 예측값 간의 차이오차는 모델이 알 수 없는 진짜 차이를 의미합니다.수식으로 표현하면:오차(Error)=실제값−진짜모집단의예측값즉, 오차는 모델이 절대로 알 수 없는 이론적인 개념입니다.2. 잔차(Residual)실제 관측된 값과 모델이 실제로 예측한 값의 차이잔차는 데이터를 가지고 계산할 수 있는 실제 값과 모델 예측값의 차이를 의미합니다.수식으로 표현하면:잔차(Residual)=실제관측값−모델의예측값즉, 잔차는 모델이 실제 데이터에서 구할 수 있는 현실적인 값입니다.오차(Error) → 모델이 절대 모르는 진짜 값과의 차이 (이론적 개념)잔차(Residual) → 모델이 실제로 예측한 값과 데이터의 차이 (현실적 개념)쉽게 오차는 '이상적인(모집단) 차이', 잔차는 '실제..