이번에는
- pandas의 문법과 다양한 메서드를 활용해 본 적이 있고, 코드를 보면 어느 정도 이해할 수 있습니다.
- matplotlib을 활용해서 데이터 시각화를 해본 적이 있고, 코드를 보면 어느 정도 이해할 수 있습니다.
- 데이터셋을 train/test 데이터셋으로 나누어서 모델을 학습 및 검증해본 경험이 있다.
목표
- 다양한 피처가 있는 데이터셋을 밑바닥부터 샅샅이 뜯어보고, 전설의 포켓몬을 분류하기 위한 피처에는 무엇이 있는지 생각해 보자.
- 모델 학습을 시작하기 전 모든 컬럼에 대해 그래프 시각화, 피벗 테이블 등을 활용하며 다양한 방법으로 충분한 EDA를 진행하자.
- 모델 학습에 넣기 위해서 전처리가 필요한 범주형/문자열 데이터에 대한 전처리를 원-핫 인코딩 등으로 적절하게 진행.
- 전체 데이터셋을 train/test 데이터셋으로 나누고, 적절한 분류 모델(Decision Tree)을 선택해 학습시키며 베이스라인과 비교하.
목차 :
- 포켓몬, 그 데이터는 어디서 구할까
(1) 안녕, 포켓몬과 인사해!
(2) 포켓몬, 그 데이터는 어디서 구할까
(3) 포켓몬 데이터 불러오기 - 전설의 포켓몬? 먼저 샅샅이 살펴보자!
(1) 결측치와 전체 칼럼
(2) ID와 이름
(3) 포켓몬의 속성
(4) 모든 스탯의 총합
(5) 세부 스탯
(6) 세대 - 전설의 포켓몬과 일반 포켓몬, 그 차이는?
(1) 전설의 포켓몬의 Total값
(2) 전설의 포켓몬의 이름 - 모델에 넣기 위해! 데이터 전처리하기
(1) 이름의 길이가 10 이상인가?
(2) 이름에 자주 쓰이는 토큰 추출
(3) Type 1 & 2! 범주형 데이터 전처리하기 - 가랏, 몬스터볼!
(1) 가장 기본 데이터로 만드는 베이스라인
(2) 의사 결정 트리 모델 학습시키기
(3) 피처 엔지니어링 데이터로 학습시키면 얼마나 차이가 날까?
(4) 의사 결정 트리 모델 다시 학습시키기
오늘은 흥미로운 포켓몬 데이터셋을 가지고 실습을 해 보겠습니다. 포켓몬의 이름, 속성, 또는 공격력이나 방어력 등과 같은 스탯 값만을 가지고 전설의 포켓몬인지 아닌지를 구별해낼 수 있을까요?
오늘은 이러한 분류 문제를 풀기 위해 데이터를 밑바닥부터 샅샅이 뜯어보는 연습을 할 것입니다.
이러한 과정을 탐색적 데이터 분석(Exploratory Data Analysis, 이하 EDA) 이라고 합니다.
EDA는 더 좋은 데이터 분석과 더 좋은 머신러닝 모델을 만들기 위해 필수적인 과정입니다.
그리고, 더 나은 성능의 모델을 만들어내기 위해서는 무엇을 고민해야 하는지, 이러한 흐름에 익숙해진다면 어떤 데이터셋을 만나더라도 충분히 빠르고 치밀하게 데이터셋을 다룰 수 있게 될 것입니다.
(출처 : 모두연 프로덕트데이터분석가1기 과정중)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import os
original_data = pd.read_csv("data/Pokemon.csv")
print('슝=3')
슝=3# original_data 변수를 그대로 사용하지 않고 원본 데이터를 담은 변수는 고이 놔둘 것입니다.
# 다음과 같이 원본 데이터를 복사해서 pokemon이라는 변수를 새로 만들어 사용
pokemon = original_data.copy()
print(pokemon.shape) #데이터셋의 크기를 출력
pokemon.head()
(800, 13)

# 데이터셋은 총 800행, 13열 포켓몬이 총 800마리이고, 각 포켓몬을 설명하는 특성(feature)은 13개라고 해석
# 타겟으로 두고 확인할 데이터는 Legendary (전설의 포켓몬인지 아닌지의 여부)이므로,
# Legendary == True 값을 가지는 레전드 포켓몬 데이터셋은 legendary 변수에,
# Legendary == False 값을 가지는 일반 포켓몬 데이터셋은 ordinary 변수에 저장
# 전설의 포켓몬 데이터셋
legendary = pokemon[pokemon["Legendary"] == True].reset_index(drop=True)
print(legendary.shape)
legendary.head()
(65, 13)# Q. 일반 포켓몬의 데이터셋도 만들어봅시다. 일반은 ["Legendary"] == False로적용
ordinary = pokemon[pokemon["Legendary"] == False].reset_index(drop=True)
print(ordinary.shape)
ordinary.head()
(735, 13)# 많은 포켓몬 데이터 속에서 전설의 포켓몬을 구별해 내려면, 무엇보다 데이터 자체를 확실히 이해하는 것이 가장 중요
# 데이터를 다루기 전 가장 기본적으로 먼저 해야 할 것! 바로 빈 데이터(결측치) 먼저 확인
pokemon.isnull().sum()
# 0
Name 0
Type 1 0
Type 2 386
Total 0
HP 0
Attack 0
Defense 0
Sp. Atk 0
Sp. Def 0
Speed 0
Generation 0
Legendary 0
dtype: int64# Type 2 컬럼에만 총 386개의 결측치가 있군요.
# Type 1이 있고 Type2도 있으므로, 뭔가 두 번째 속성이 없는 포켓몬이 있는 것 같습니다.
# 데이터셋을 다룰 때 빈 데이터를 다루는 것은 매우 조심스러운 일입니다.
# 데이터셋의 성격에 따라 빈 데이터를 어떻게 다루어야 할지에 대한 방법이 달라지기 때문
#전체 컬럼 이해하기
print(len(pokemon.columns)) # 전체 컬럼 출력
pokemon.columns
13
Index(['#', 'Name', 'Type 1', 'Type 2', 'Total', 'HP', 'Attack', 'Defense',
'Sp. Atk', 'Sp. Def', 'Speed', 'Generation', 'Legendary'],
dtype='object')# : 포켓몬 Id number. 성별이 다르지만 같은 포켓몬인 경우 등은 같은 #값을 가진다. int
# Name : 포켓몬 이름. 포켓몬 각각의 이름으로 저장되고, 800개의 포켓몬의 이름 데이터는 모두 다르다. (unique) str
# Type 1 : 첫 번째 속성. 속성을 하나만 가지는 경우 Type 1에 입력된다. str
# Type 2 : 두 번째 속성. 속성을 하나만 가지는 포켓몬의 경우 Type 2는 NaN(결측값)을 가진다. str
# Total : 전체 6가지 스탯의 총합. int
# HP : 포켓몬의 체력. int
# Attack : 물리 공격력. (scratch, punch 등) int
# Defense : 물리 공격에 대한 방어력. int
# Sp. Atk : 특수 공격력. (fire blast, bubble beam 등) int
# Sp. Def : 특수 공격에 대한 방어력. int
# Speed : 포켓몬 매치에 대해 어떤 포켓몬이 먼저 공격할지를 결정. (더 높은 포켓몬이 먼저 공격한다) int
# Generation : 포켓몬의 세대. 현재 데이터에는 6세대까지 있다. int
# Legendary : 전설의 포켓몬 여부. !! Target feature !! bool
# 총 몇 종류의 # 값이 있는지 확인
len(set(pokemon["#"]))
721# 전체 데이터는 총 800개인데 #컬럼을 집합으로 만든 자료형은 그보다 작은 721개의 데이터를 가집니다.
# 파이썬의 집합(set) 자료형은 중복 데이터를 가질 수 없다 따라서 집합의 크기가 800이 아니라 721이므로
# # 컬럼의 값은 unique하지 않으며(index로 쓸 수 없으며), 같은 번호를 가지는 컬럼들이 있음을 알 수 있다.
# 같은 # 값을 가지는 포켓몬을 확인
pokemon[pokemon["#"] == 6]

# #6의 포켓몬은 Charizard, CharizardMega Charizard X, CharizardMega Charizard Y 세 개로 나뉨
# 기본 포켓몬인 Charizard(리자몽)로부터 시작해서 진화한 Mega Charizard가 있고,
# X, Y는 버전을 나타내는 것으로 보입니다.
# 이름은 문자열로 나타나는 데이터.
# 모든 포켓몬은 이름을 갖고 있죠. 특별하게 확인할 것은 없는 것 같고,
# 혹시 모든 이름이 유일한 이름인지만 확인해 보자
# len(...)집합의 길이를 출력하여 유일한 포켓몬 이름의 개수를 확인
print(len(set(pokemon["Name"]))) #포켓몬 이름 컬럼을 집합(set)으로 변환하여 중복을 제거
800# 각 포켓몬의 속성을 무작위로 두 마리의 포켓몬을 한번 살펴보자
pokemon.loc[[6, 10]]

# 6번 포켓몬인 Charizard는 Fire와 Flying 속성 두 가지를,
# 8번 포켓몬인 Wartortle은 Water 속성 단 한 가지만 가진다.
# 각 속성의 종류는 총 몇 가지인지 알아보자
len(list(set(pokemon["Type 1"]))), len(list(set(pokemon["Type 2"])))
(18, 19)# Type 1에는 총 18가지, Type 2에는 총 19가지의 속성
# 여기서 Type 2가 한 가지 더 많은 것은 뭘까?
# 각자를 집합으로 만들어 차집합을 확인
set(pokemon["Type 2"]) - set(pokemon["Type 1"])
{nan}# 둘의 차집합이 NaN 데이터이니 나머지 18가지 속성은 Type 1, Type 2 모두 같은 세트의 데이터를 알 수 있다
# 포켓몬들의 모든 Type을 types 변수에 저장
types = list(set(pokemon["Type 1"]))
print(len(types))
print(types)
18
['Ice', 'Steel', 'Normal', 'Fighting', 'Dark', 'Ghost', 'Dragon', 'Psychic', 'Fairy', 'Flying', 'Rock', 'Grass', 'Fire', 'Water', 'Electric', 'Bug', 'Ground', 'Poison']# 그렇다면 Type을 하나만 가지고 있는 포켓몬은 몇 마리일까?
# Type이 단 하나뿐이라면 Type 2는 NaN 값일 것이니 Type 2가 NaN인 포켓몬의 수를 구해보자
# 데이터가 비어있는 NaN값의 개수를 확인하고 싶을 때는 isna() 함수를 활용
pokemon["Type 2"].isna().sum()
386# 총 386개의 포켓몬은 속성을 하나만 가지고, 나머지는 두 개의 속성을 가진다.
# Type 1 데이터 분포 plot
# 일반 포켓몬과 전설의 포켓몬 속성 분포가 각각 어떤지?
# 이 데이터는 일반 포켓몬보다 전설의 포켓몬 수가 매우 적은 불균형 데이터이기 때문에,
# 전설의 포켓몬은 따로 시각화해 주는 것이 좋을 것 같다.
# plt의 subplot을 활용해서 두 개의 그래프를 한 번에 그리면서,
# 그래프는 sns(seaborn)의 countplot을 활용. countplot은 말 그대로 데이터의 개수를 표시하는 플롯
# palette="pastel" 또는 palette="Set2" 등의 컬러 팔레트를 추가하면 여러 색상으로 표현
# palette에는 sns.color_palette("husl"), "coolwarm", "viridis" 등 다양한 컬러 스타일을 사용할 수 있다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12, 7)) # 그래프 크기 설정 12는 가로길이
plt.subplot(211)
sns.countplot(data=ordinary, x="Type 1", order=types, palette="Set2").set_xlabel('')
plt.title("[Ordinary Pokemons]")
plt.subplot(212)
sns.countplot(data=legendary, x="Type 1", order=types, palette="Set3").set_xlabel('')
plt.title("[Legendary Pokemons]")
plt.show()

1. 일반 포켓몬(Ordinary Pokemons)의 속성 분포
- Normal 타입이 가장 많은 비율을 차지하며, Water 타입도 매우 많음.
- Grass, Fire, Electric, Bug 속성도 비교적 많은 개수를 차지함.
- 다양한 속성들이 비교적 고르게 분포됨.
- Flying 타입의 개수는 거의 없음.
2. 전설의 포켓몬(Legendary Pokemons)의 속성 분포
- Dragon과 Psychic 속성이 가장 높은 비율을 차지.
- Grass, Water, Electric, Fire 타입도 어느 정도 분포됨.
- Normal 타입의 전설의 포켓몬은 거의 없음.
- Fairy, Flying, Dark, Ground 등 일부 속성은 일반 포켓몬보다 적은 개수
3. 일반 포켓몬과 전설의 포켓몬의 주요 차이점
- Normal 타입의 차이
- 일반 포켓몬에서는 Normal 타입이 가장 많지만, 전설의 포켓몬에서는 거의 없음.
- 이는 Normal 타입이 주로 평범한 포켓몬들에게 부여되는 속성이라는 점을 반영.
- Dragon과 Psychic 타입의 차이
- 전설의 포켓몬에서는 Dragon과 Psychic 속성이 압도적으로 많음.
- 이는 강력한 포켓몬들이 주로 드래곤이나 초능력 계열로 설정되는 경향을 반영.
- Flying 타입의 차이
- 일반 포켓몬에서는 Flying 속성이 거의 없지만, 전설의 포켓몬에서도 많지 않음.
- Flying 타입이 단독 속성으로 존재하는 경우가 적고, 다른 타입과 혼합된 경우가 많기 때문.
- Water, Grass, Fire 타입
- 일반 포켓몬과 전설의 포켓몬 모두 Water, Grass, Fire 타입이 적절히 분포.
- 그러나 전설의 포켓몬에서는 상대적으로 Dragon과 Psychic 비중이 더 높음.
결론
- 일반 포켓몬: Normal, Water, Grass, Fire 속성이 많고 비교적 균형 잡힌 분포.
- 전설의 포켓몬: Dragon, Psychic 타입이 두드러지며, Normal 속성은 거의 없음.
- 전설의 포켓몬은 강한 인상을 주기 위해 특정 속성(특히 Dragon과 Psychic)이 집중적으로 분포하는 반면, 일반 포켓몬은 다양한 속성이 균형 있게 포함됨
이 차이를 기반으로, 전설의 포켓몬은 강력한 속성 위주로 구성되고, 일반 포켓몬은 다양한 환경에서 등장하는 여러 속성을 가진다는 점을 알 수 있다.
# 일반 포켓몬: Normal, Water, Grass, Fire 속성이 많고 비교적 균형 잡힌 분포.
# 전설의 포켓몬: Dragon, Psychic 타입이 두드러지며, Normal 속성은 거의 없음.
# 전설의 포켓몬은 강한 인상을 주기 위해 특정 속성 특히, Dragon과 Psychic이 집중적으로 분포하는 반면, 일반 포켓몬은 다양한 속성이 균형 있게 포함.
# 피벗 테이블(pivot table)로 각 속성에 Legendary 포켓몬들이 몇 퍼센트씩 있는지 확인하자
# Type1별로 Legendary의 비율을 보여주는 피벗 테이블
pd.pivot_table(pokemon, index="Type 1", values="Legendary").sort_values(by=["Legendary"], ascending=False)

# Legendary 비율이 가장 높은 속성은 Flying 으로, 50%의 비율
# Type 2 데이터 분포 plot
# Type 2에는 NaN(결측값)이 존재했었다. Countplot을 그릴 때는 결측값은 자동으로 제외된다.
plt.figure(figsize=(12, 10)) # 화면 해상도에 따라 그래프 크기를 조정
# Ordinary Pokemons의 Type 2 분포
plt.subplot(211)
sns.countplot(data=ordinary, x="Type 2", order=ordinary["Type 2"].dropna().unique(), palette="Set2")
plt.title("[Ordinary Pokemons]")
# Legendary Pokemons의 Type 2 분포
plt.subplot(212)
sns.countplot(data=legendary, x="Type 2", order=legendary["Type 2"].dropna().unique(), palette="Set3")
plt.title("[Legendary Pokemons]")
plt.show()

# Type 2 또한 일반 포켓몬과 전설의 포켓몬 분포 차이가 보입니다.
# Flying 속성의 경우 두 경우 다 가장 많지만, 일반 포켓몬에는 Grass, Rock, Poison같은 속성이 많은 반면
# 전설의 포켓몬은 하나도 없다.
# 대신 여전히 Dragon, Psychic과 더불어 Fighting과 같은 속성이 많다.
# Q. Type 2에 대해서도 피벗 테이블을 만들어봅시다.
# Type 2에 대한 피벗 테이블 생성
type2_pivot = pokemon.pivot_table(index="Type 2", values="Name", aggfunc="count").fillna(0)
# 결과 출력
from IPython.display import display
display(type2_pivot)

# 피벗테이블 실수로 다시 작성
pd.pivot_table(pokemon, index="Type 2", values="Legendary").sort_values(by=["Legendary"], ascending=False)
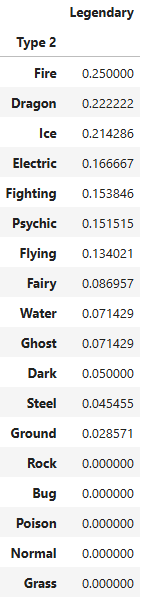
# Type 2에서는 Fire 속성 포켓몬의 Legendary 비율이 25%로 가장 높다.
# 데이터셋에서 포켓몬은 총 6가지의 스탯 값을 가집니다.
# 포켓몬 데이터의 Total 컬럼은 이 6가지 속성값의 총합입니다.
# 모든 스탯의 종류를 stats라는 변수에 저장해 보자.
stats = ["HP", "Attack", "Defense", "Sp. Atk", "Sp. Def", "Speed"]
stats
['HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed']# 실제로 6개 스탯의 총합과 데이터에 제공된 Total값이 맞는지 확인
# 첫 번째 포켓몬에 대해 검증하는 코드
print("#0 pokemon: ", pokemon.loc[0, "Name"])
print("total: ", int(pokemon.loc[0, "Total"]))
print("stats: ", list(pokemon.loc[0, stats]))
print("sum of all stats: ", sum(list(pokemon.loc[0, stats])))
#0 pokemon: Bulbasaur
total: 318
stats: [45, 49, 49, 65, 65, 45]
sum of all stats: 318# 첫 번째 포켓몬에 대해서는 Total 값이 318로 일치
# 전체 포켓몬에 대해 Total 값이 stats의 총합과 같은지 확인
# stats 컬럼 리스트 (예: HP, Attack, Defense, Sp. Atk, Sp. Def, Speed)
stats = ["HP", "Attack", "Defense", "Sp. Atk", "Sp. Def", "Speed"]
# 'Total' 값과 'stats'의 총합이 같은 포켓몬 수 계산
matching_count = sum(pokemon['Total'].values == pokemon[stats].sum(axis=1).values)
# 결과 출력
print("Total 값과 stats의 총합이 같은 포켓몬의 수:", matching_count)
Total 값과 stats의 총합이 같은 포켓몬의 수: 800# Total값에 따른 분포 plot
# Total 값과 Legendary 는 어떤 관계가 있을지 확인
fig, ax = plt.subplots()
fig.set_size_inches(12, 6) # 화면 해상도에 따라 그래프 크기를 조정해 주세요.
sns.scatterplot(data=pokemon, x="Type 1", y="Total", hue="Legendary")
plt.show()

# Legendary 여부에 따라 색깔(hue)을 달리하도록 했습니다. 점의 색깔을 보면 Type 1 별로 Total 값을 확인했을 때,
# 전설의 포켓몬은 주로 Total 스탯 값이 높다는 것이 확인
# 세부스탯: HP, Attack, Defense, Sp. Atk, Sp. Def, Speed
# 각각의 스탯 값은 어떻게 분포되어 있을까요? subplot으로 여러 그래프를 한 번에 확인
# 그래프 설정 (3x2 subplot)
figure, ((ax1, ax2), (ax3, ax4), (ax5, ax6)) = plt.subplots(nrows=3, ncols=2)
figure.set_size_inches(12, 18) # 그래프 크기 조정
# "HP" 스탯의 scatter plot
sns.scatterplot(data=pokemon, y="Total", x="HP", hue="Legendary", ax=ax1)
ax1.set_title("HP vs Total")
# "Attack" 스탯의 scatter plot
sns.scatterplot(data=pokemon, y="Total", x="Attack", hue="Legendary", ax=ax2)
ax2.set_title("Attack vs Total")
# "Defense" 스탯의 scatter plot
sns.scatterplot(data=pokemon, y="Total", x="Defense", hue="Legendary", ax=ax3)
ax3.set_title("Defense vs Total")
# "Sp. Atk" 스탯의 scatter plot
sns.scatterplot(data=pokemon, y="Total", x="Sp. Atk", hue="Legendary", ax=ax4)
ax4.set_title("Sp. Atk vs Total")
# "Sp. Def" 스탯의 scatter plot
sns.scatterplot(data=pokemon, y="Total", x="Sp. Def", hue="Legendary", ax=ax5)
ax5.set_title("Sp. Def vs Total")
# "Speed" 스탯의 scatter plot
sns.scatterplot(data=pokemon, y="Total", x="Speed", hue="Legendary", ax=ax6)
ax6.set_title("Speed vs Total")
# 그래프 표시
plt.show()

# 각 스탯에 대한 분석
# HP, Defense, Sp. Def
# 전설의 포켓몬은 주로 높은 스탯을 갖지만, 이 세 가지에서는 일반 포켓몬이 전설의 포켓몬보다
# 특히 높은 몇몇 포켓몬이 있습니다.
# 그러나 그 포켓몬들도 Total 값은 특별히 높지 않은 것으로 보아 특정 스탯만 특별히 높은, 즉 특정 속성에
# 특화된 포켓몬들로 보입니다. (ex. 방어형, 공격형 등)
# Attack, Sp. Atk, Speed 이 세 가지 스탯은 Total과 거의 비례합니다.
# 전설의 포켓몬이 각 스탯의 최대치를 차지하고 있습니다.
# Generation : 포켓몬의 세대
# Generation은 각 포켓몬의 "세대"로, 현재 데이터셋에는 1~6세대의 포켓몬이 존재합니다.
# 각 세대에 대한 포켓몬의 수를 확인
plt.figure(figsize=(12, 10)) # 그래프 크기 조정
# Ordinary Pokemons 세대별 개수 분포
plt.subplot(211)
sns.countplot(data=ordinary, x="Generation", palette="Set2").set_xlabel('')
plt.title("[Ordinary Pokemons]")
# Legendary Pokemons 세대별 개수 분포
plt.subplot(212)
sns.countplot(data=legendary, x="Generation", palette="Set1").set_xlabel('')
plt.title("[Legendary Pokemons]")
plt.show()

# 전설의 포켓몬은 1, 2세대에는 많지 않았나 보네요. 3세대부터 많아졌다가, 6세대에 다시 줄어든 것을 확인할 수 있습니다.
# 여기까지 전체 데이터셋의 모든 컬럼에 대해 일차적으로 살펴보았습니다
계속이어서 작성 중
'데이터 분석가:Applied Data Analytics > 판다스 데이터분석' 카테고리의 다른 글
| geopy 설치 (0) | 2025.02.19 |
|---|---|
| 신용거래 이상탐지 데이터 다루기 (0) | 2025.02.19 |
| 데이터 정제 과정에서 사용하는 Pandas 메소드 (2) | 2025.02.18 |
| 5. Feature Engineering - 스피드 데이팅 데이터 다루기 (0) | 2025.02.18 |
| Feature Engineering (1) | 2025.02.18 |