아래내용은 모두연의 프로덕트데이터분석1기 수업내용중에 정리한 겁니다.
Pandas : 파이썬을 지원하는 페키지
Dataframe : 판다스에서 제공하는 데이터(엑셀과 비슷하다)
- index, row(행), column(열, 변수, Feature)
- 독립변수를 잘 활용해서 종속변수를 예측
data.head()
data.tail() : 뒷에 5
일반적으로 1: yes, 0:No
data.info() : 컬럼에 대한 정보, 데이터라인, 컬럼몇개, 내용 제대로 들어가있는 데이터값, Dtype(데이터 타입) 을 알려줌
data.describe() : object를 뺀 숫자형태의 데이터를 보여줌
교육과정중에 자주 등장하는 메소드 10개 입니다. 숙지 하셨다가 잘 활용해 보세요.!!
NO.메소드설명| 1. | .describe() | DataFrame 또는 Series 객체에 대한 요약 통계를 제공합니다. 이 메소드는 데이터의 중심 경향, 분포 및 형태 등을 빠르게 이해하는 데 도움이 됩니다. |
| 2. | .apply() | 함수를 데이터프레임의 열 또는 행에 적용 합니다.<예시> 데이터 프레임의 모든 수치 데이터에 2를 곱합니다. |
| 3. | .sort_values() | DataFrame 또는 Series 내의 값에 따라 데이터를 정렬하는 데 사용됩니다. 데이터를 오름차순 또는 내림차순으로 정렬할 수 있으며, 복수의 열을 기준으로 정렬하는 것도 가능합니다. |
| 4. | .tail() | DataFrame 또는 Series 객체의 끝에서부터 지정된 수의 행을 반환합니다. 최신 데이터셋을 확인할 때 유용한데 데이터 크기가 큰 경우에 전체 데이터를 로드하지 않고도 빠른 데이터 검토를 할 수 있도록 도와줍니다. |
| 5. | .replace() | 특정 값을 다른 값으로 대체 <예시> 데이터 프레임의 'A' 열에서 'apple'을 'orange'로 바꿉니다. |
| 6. | pd.to_numeric() | 문자열이나 다른 타입의 데이터를 숫자형(정수형 또는 부동소수점형)으로 변환하는 데 사용됩니다. |
| 7. | .get_dummies() | 주어진 범주형 열의 각 고유 범주를 대표하는 새로운 이진(0 또는 1) 열을 생성합니다. |
| 8. | Aggregation | 여러 데이터 포인트를 요약하고, 그룹화하여 새로운 통계 또는 정보를 추출하는 과정입니다. groupby(), 집계 함수, std(), agg()등 |
| 9. | .merge() | 두 개 이상의 데이터 프레임을 특정 공통 열 또는 인덱스를 기준으로 병합하는 데 사용됩니다. SQL의 JOIN과 유사한 기능을 제공합니다. |
| 10. | .value_counts() | 범주형 데이터를 요약하는 데이터 분석 작업에 자주 사용됩니다. |
data.('컬럼이름(하나값만쓸수있다)') : 컬럼 두개는 ()로부분하면 된다. 컬럼의 내용볼 수 있다.
판다스 시리즈는 한줄만 받아들인다, 와 데이터프레임 구분된다.
import numpy as np 는 컴퓨터 입장에서 데이터를 다룰때 빠르고 유리하다.
numpy로 변환해서 하는경우
데이터 크리닝은 정답이 없이 상황에 맞게 하면 된다. 보통 모델링을 목정으로 하는 크리닝은 불필요한 데이터는 정리하는게 좋다.
1-3. 불필요한 컬럼 삭제 (Dropping columns), 누락된 결측치 처리 (Missing values)
data.drop('Name', axis = 1, implace = True)
data.head()
data.drop(2, axis = 0)
data.drop(2)
data.drop(['Pclass','Age'], axis = 1) : 컬럼을 하나이상 삭제시
데이터의 컬럼 중 'Name', 'Ticket', 'ticket_date'을 동시에 삭제하고, 삭제한 데이터를 dt_data로 저장.
결측치 개수: 2, 비율: 0.23%data.isna().mean() : 컬럼별 결측치의 비율을 보여줌
isna()로 결측치(Null)를 삭제해줘야 머신러닝을 위해서 최선을 선택할 필요가 있다.
- 결측치가 있는 행을 삭제
- 결측치를 평균으로 채우는것
- 결측치가 있는 열을 삭제한다.
data.describe()로 전체 나온 값을 확인
이상적인 값을 넘어서는 : outliner (min, max 등 값이 확 튀는 값이 있는경우이므로)
정규분포란? 정규분포는 데이터가 특정 평균값을 중심으로 양쪽으로 균등하게 분포하는 모양을 나타냅니다.
이 분포는 종 모양을 하고 있어 '종 모양 곡선'이라고도 불립니다. 정규분포에서는 대부분의 데이터가 평균값 근처에 몰려 있으며, 평균에서 멀어질수록 데이터의 빈도가 줄어듭니다.
예를 들어, 대학생들의 시험 점수가 정규분포를 이룬다면, 대부분의 학생들은 평균 점수 근처에 점수를 받을 것이고, 매우 높거나 매우 낮은 점수를 받는 학생은 적을 것입니다.
Matplotlib vs Seaborn vs distplot vs scatterplot vs boxplot 차이점
1️⃣ Matplotlib vs Seaborn (라이브러리 차이)
라이브러리 / 특징 / 사용 용도
| Matplotlib | 기본적인 데이터 시각화 라이브러리 | 선 그래프, 바 차트, 산점도 등 기본적인 그래프 |
| Seaborn | Matplotlib 기반의 고급 스타일 제공 | 통계적 시각화에 강함, 데이터 분석에 특화된 그래프 |
기억하는 법:
✔ Matplotlib → “기본 그래프” (단순한 그래프도 직접 꾸며야 함)
✔ Seaborn → “고급 그래프” (깔끔한 스타일 제공, 데이터 분석에 유용)
2️⃣ 각 그래프 (distplot vs scatterplot vs boxplot) 차이
그래프 / 기능 / 사용 목적
| distplot | 히스토그램 + 커널 밀도 함수(KDE) | 데이터 분포(숫자형 변수) 확인 |
| scatterplot | 산점도 (점 그래프) | 두 변수의 관계를 시각화 |
| boxplot | 박스플롯 (중앙값, IQR, 이상치 표시) | 데이터 분포와 이상치 탐색 |
기억하는 법:
✔ distplot → "데이터 분포를 보고 싶을 때!"
✔ scatterplot → "두 변수의 관계를 보고 싶을 때!"
✔ boxplot → "이상치와 분포를 한눈에 보고 싶을 때!"
3️⃣ 코드 예제 및 그래프 설명
① distplot (데이터 분포)
import matplotlib.pyplot as plt
# 예제 데이터
import numpy as np
data = np.random.randn(1000) # 정규분포를 따르는 난수 1000개
# distplot (히스토그램 + KDE)
sns.histplot(data, kde=True) # 최신 Seaborn에서는 distplot 대신 histplot 사용
plt.show()
✔ 히스토그램(막대) + **커널 밀도 함수(KDE)**를 함께 보여줌
✔ 데이터가 **어떤 분포(정규분포, 치우친 분포 등)**를 따르는지 확인할 때 사용
② scatterplot (산점도, 변수 간 관계)
import matplotlib.pyplot as plt
# 예제 데이터
import pandas as pd
np.random.seed(10)
df = pd.DataFrame({
'x': np.random.rand(100),
'y': np.random.rand(100) * 2
})
# scatterplot (산점도)
sns.scatterplot(x='x', y='y', data=df)
plt.show()
✔ 점(산점도)으로 데이터 분포를 나타냄
✔ 두 변수 x와 y의 상관관계(패턴 존재 여부) 확인할 때 사용
③ boxplot (박스플롯, 이상치 탐색)
import matplotlib.pyplot as plt
# 예제 데이터
df = pd.DataFrame({
'group': ['A']*50 + ['B']*50,
'value': np.concatenate([np.random.randn(50)*10 + 50, np.random.randn(50)*10 + 60])
})
# boxplot (박스플롯)
sns.boxplot(x='group', y='value', data=df)
plt.show()
✔ 데이터의 중앙값, 사분위수(Q1~Q3), 이상치를 한눈에 확인 가능
✔ 그룹별 데이터 분포 비교할 때 유용
최종 정리
1️⃣ Matplotlib → 기본 그래프 (세부 스타일 직접 설정해야 함)
2️⃣ Seaborn → 더 예쁜 스타일 제공 (데이터 분석에 강력함)
✔ distplot → "데이터 분포를 확인" (히스토그램 + KDE)
✔ scatterplot → "두 변수의 관계를 확인" (산점도)
✔ boxplot → "이상치 & 분포를 확인" (박스플롯)
import pandas as pd
pd.read_csv('data/titanic.csv')
import matplotlib.pyplot as plt
import seaborn as sns
sns.displot(data['SibSp'])

sns.displot(data['Age'])

sns.scatterplot(x = data.index, y = data['Age'])

sns.scatterplot(x = data.index, y = data['SibSp'])

sns.boxplot(data['Age']) # 같은 코드인데 Age값이 x축에 있는 그래프로 나타나기도 하네요

sns.boxplot(x=titanic_df['Age']) #X축으로 표현하기 위한

sns.boxplot(data['SibSp'])

data = data.assign(Age=data['Age'].apply(lambda x: 70 if x > 70 else x)).sort_values(by='Age', ascending=False)
display(data)

1-5. 중복 데이터 처리 및 데이터 형태 변환처리(Removing duplicate data, apply, map, replace, rename)
replace vs map vs apply 차이점
1️⃣ replace (값을 직접 바꿈)
사용 목적특정 값(또는 여러 값)을 다른 값으로 치환
| 특징 | 딕셔너리 또는 리스트를 사용하여 값을 직접 변경 |
| 적용 대상 | Series, DataFrame 전체 가능 |
예제 코드
data = pd.DataFrame({'Gender': ['M', 'F', 'M', 'F', 'M']})
# 'M' → 'Male', 'F' → 'Female'로 변환
data['Gender'] = data['Gender'].replace({'M': 'Male', 'F': 'Female'})
print(data)
🔹 출력 결과
Gender
0 Male
1 Female
2 Male
3 Female
4 Male쉽게 기억하는 법:
✔ replace(바꿀값: 새값) → 값 자체를 변경할 때 사용!
2️⃣ map (1:1 값 변환)
사용 목적 / 딕셔너리, 함수 사용하여 값 변환 (1:1 매핑)
| 특징 | 딕셔너리를 사용해 특정 값들을 다른 값으로 변경 |
| 적용 대상 | Series에만 사용 가능! (DataFrame 전체 적용 불가) |
예제 코드
# 점수로 변환 (A → 90, B → 80, C → 70)
data['Grade'] = data['Grade'].map({'A': 90, 'B': 80, 'C': 70})
print(data)
🔹 출력 결과
Grade
0 90
1 80
2 70
3 90
4 80쉽게 기억하는 법:
✔ map(딕셔너리) → 한 개의 값만 바꿀 때, 1:1 매칭!
✔ DataFrame 전체 적용 ❌ → Series에만 가능!
3️⃣ apply (함수 용)
사용 목적 / 데이터를 가공해야 할 때 (조건문, 계산 등)
| 특징 | 람다 함수 또는 일반 함수를 사용해 복잡한 변환 가능 |
| 적용 대상 | Series, DataFrame 전체 가능 |
예제 코드 (Age > 70이면 70으로 변경)
# 70 초과 값은 70으로 변환
data['Age'] = data['Age'].apply(lambda x: 70 if x > 70 else x)
print(data)
🔹 출력 결과
Age
0 65
1 70
2 70
3 50
4 70
쉽게 기억하는 법:
✔ apply(함수) → 조건문, 계산 등 자유로운 변환 가능!
✔ DataFrame 전체, Series 둘 다 가능!
최종 정리
메서드 / 용도 / 적용 대상 / 사용 방식
| replace | 특정 값을 다른 값으로 직접 치환 | Series, DataFrame | replace({'A': 'X', 'B': 'Y'}) |
| map | 1:1 값 매칭 (딕셔너리 or 함수) | Series만 가능 | map({'A': 1, 'B': 2}) |
| apply | 복잡한 변환 (조건문, 계산 등) | Series, DataFrame | apply(lambda x: x+1 if x > 10 else x) |
상황에 따라 replace, map, apply를 언제 써야 할지 아는게 좋다.
import pandas as pd
pd.read_csv('data/titanic.csv')
data = pd.read_csv('data/titanic.csv')
data.duplicated()
0 False
1 False
2 False
3 False
4 False
...
880 False
881 False
882 False
883 False
884 False
Length: 885, dtype: booldata[data.duplicated()]

data[data['Name'] == 'Palsson, Miss. Torborg Danira'] #결과확인 후 이런값은 Drop하는게 좋다

data = data.rename({'Gendr': 'Gender'}, axis = 1)
data.rename({0: 'a', 1: 'b', 2: 'c'})

data['Embarked'].replace({'S': 'Southampton', 'C': 'Cherbourg', 'Q': 'Queenstown'})# Embarked중에서 replace 내용에 값을 바꾼다

data.replace({'S': 'Southampton', 'C': 'Cherbourg', 'Q': 'Queenstown'}) #모든 값을 바꿔준다
data['Embarked'].map({'S': 'Southampton', 'C': 'Cherbourg', 'Q': 'Queenstown'}) #replace 대신 map해도 결과 동일
data = data.rename({'Gendr': 'Gender'}, axis=1)
data['Gender'] = data['Gender'].replace({'male': 0, 'female': 1}) # 값 변환
print(data)

1-6. 텍스트 처리 (Text handling)
data.head()

data['Ticket'][-5:]
880 211536
881 112053
882 W./C. 6607
883 111369
884 370376
Name: Ticket, dtype: objectdata['Ticket'].str[-5:]
0 21171
1 17599
2 01282
3 13803
4 73450
...
880 11536
881 12053
882 6607
883 11369
884 70376
Name: Ticket, Length: 882, dtype: objectdata['Ticket'].str.split()
0 [A/5, 21171]
1 [PC, 17599]
2 [STON/O2., 3101282]
3 [113803]
4 [373450]
...
880 [211536]
881 [112053]
882 [W./C., 6607]
883 [111369]
884 [370376]
Name: Ticket, Length: 882, dtype: object
data['Ticket'].str.split(expand = True)

data['Ticket'].str.split().apply(lambda x: x[-1])
0 21171
1 17599
2 3101282
3 113803
4 373450
...
880 211536
881 112053
882 6607
883 111369
884 370376
Name: Ticket, Length: 882, dtype: object
data['new_ticket'] = data['Ticket'].str.split().apply(lambda x: x[-1])
data

data.info()
<class 'pandas.core.frame.DataFrame'>
Index: 882 entries, 0 to 884
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 882 non-null int64
1 Name 882 non-null object
2 Gender 882 non-null int64
3 Age 876 non-null float64
4 SibSp 882 non-null int64
5 Parch 882 non-null int64
6 Ticket 882 non-null object
7 Embarked 880 non-null object
8 Survived 882 non-null int64
9 ticket_date 882 non-null object
10 new_ticket 882 non-null object
dtypes: float64(1), int64(5), object(5)
memory usage: 115.0+ KB
data[~data['new_ticket'].str.isdigit()] #new_ticket에 숫자가 아닌 LINE이 있는게 학인된다.

data['new_ticket'].replace({'LINE': '999999'}) # 임이 값인 999999으로 바꿔준다
0 21171
1 17599
2 3101282
3 113803
4 373450
...
880 211536
881 112053
882 6607
883 111369
884 370376
Name: new_ticket, Length: 882, dtype: object
data['new_ticket'].astype('int')
0 21171
1 17599
2 3101282
3 113803
4 373450
...
880 211536
881 112053
882 6607
883 111369
884 370376
Name: new_ticket, Length: 882, dtype: int32
pd.to_numeric(data['new_ticket'])
0 21171
1 17599
2 3101282
3 113803
4 373450
...
880 211536
881 112053
882 6607
883 111369
884 370376
Name: new_ticket, Length: 882, dtype: int64
data['new_ticket'] = pd.to_numeric(data['new_ticket'])
data.info()
<class 'pandas.core.frame.DataFrame'>
Index: 882 entries, 0 to 884
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 882 non-null int64
1 Name 882 non-null object
2 Gender 882 non-null int64
3 Age 876 non-null float64
4 SibSp 882 non-null int64
5 Parch 882 non-null int64
6 Ticket 882 non-null object
7 Embarked 880 non-null object
8 Survived 882 non-null int64
9 ticket_date 882 non-null object
10 new_ticket 882 non-null int64
dtypes: float64(1), int64(6), object(4)
memory usage: 115.0+ KB
| %a | Weekday as locale’s abbreviated name. |
Sun, Mon, …, Sat (en_US);
So, Mo, …, Sa (de_DE)
|
(1) |
| %A | Weekday as locale’s full name. |
Sunday, Monday, …, Saturday (en_US);
Sonntag, Montag, …, Samstag (de_DE)
|
(1) |
| %w | Weekday as a decimal number, where 0 is Sunday and 6 is Saturday. | 0, 1, …, 6 | |
| %d | Day of the month as a zero-padded decimal number. | 01, 02, …, 31 | (9) |
| %b | Month as locale’s abbreviated name. |
Jan, Feb, …, Dec (en_US);
Jan, Feb, …, Dez (de_DE)
|
(1) |
| %B | Month as locale’s full name. |
January, February, …, December (en_US);
Januar, Februar, …, Dezember (de_DE)
|
(1) |
| %m | Month as a zero-padded decimal number. | 01, 02, …, 12 | (9) |
| %y | Year without century as a zero-padded decimal number. | 00, 01, …, 99 | (9) |
| %Y | Year with century as a decimal number. | 0001, 0002, …, 2013, 2014, …, 9998, 9999 | (2) |
| %H | Hour (24-hour clock) as a zero-padded decimal number. | 00, 01, …, 23 | (9) |
| %I | Hour (12-hour clock) as a zero-padded decimal number. | 01, 02, …, 12 | (9) |
| %p | Locale’s equivalent of either AM or PM. |
AM, PM (en_US);
am, pm (de_DE)
|
(1), (3) |
| %M | Minute as a zero-padded decimal number. | 00, 01, …, 59 | (9) |
| %S | Second as a zero-padded decimal number. | 00, 01, …, 59 | (4), (9) |
| %f | Microsecond as a decimal number, zero-padded to 6 digits. | 000000, 000001, …, 999999 | (5) |
| %z | UTC offset in the form ±HHMM[SS[.ffffff]] (empty string if the object is naive). | (empty), +0000, -0400, +1030, +063415, -030712.345216 | (6) |
| %Z | Time zone name (empty string if the object is naive). | (empty), UTC, GMT | (6) |
| %j | Day of the year as a zero-padded decimal number. | 001, 002, …, 366 | (9) |
| %U | Week number of the year (Sunday as the first day of the week) as a zero-padded decimal number. All days in a new year preceding the first Sunday are considered to be in week 0. | 00, 01, …, 53 | (7), (9) |
| %W | Week number of the year (Monday as the first day of the week) as a zero-padded decimal number. All days in a new year preceding the first Monday are considered to be in week 0. | 00, 01, …, 53 | (7), (9) |
| %c | Locale’s appropriate date and time representation. |
Tue Aug 16 21:30:00 1988 (en_US);
Di 16 Aug 21:30:00 1988 (de_DE)
|
(1) |
| %x | Locale’s appropriate date representation. |
08/16/88 (None);
08/16/1988 (en_US);
16.08.1988 (de_DE)
|
(1) |
| %X | Locale’s appropriate time representation. |
21:30:00 (en_US);
21:30:00 (de_DE)
|
(1) |
| %% | A literal '%' character. | % |
str 메서드 vs dt 메서드 차이점
1️⃣ str 메서드 (문자열 조작)
특징설명
| 사용 대상 | 문자열(object 타입) 컬럼 |
| 기능 | 문자열 변환, 대소문자 변경, 패턴 추출, 공백 제거 등 |
| 대표 함수 | lower(), upper(), replace(), split(), contains() 등 |
예제 코드 (str 메서드 활용)
🔹 출력 결과
Name Name_lower First_Name Has_Smith
0 Alice Johnson alice johnson Alice False
1 Bob Smith bob smith Bob True
2 Charlie Brown charlie brown Charlie False
기억하기 쉽게!
✔ str.lower() → 소문자로 변환
✔ str.split().str[0] → 첫 번째 단어 가져오기
✔ str.contains('Smith') → 특정 단어 포함 여부 확인
2️⃣ dt 메서드 (날짜/시간 조작)
특징 / 설명
| 사용 대상 | 날짜(datetime64) 컬럼 |
| 기능 | 연, 월, 일, 요일, 시간 추출, 날짜 연산 |
| 대표 함수 | year, month, day, weekday(), hour, minute 등 |
예제 코드 (dt 메서드 활용)
🔹 출력 결과
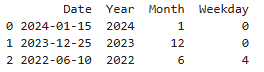
기억하기 쉽게!
✔ dt.year → 연도 추출
✔ dt.month → 월 추출
✔ dt.weekday → 요일 추출 (0=월요일, 6=일요일)
최종 정리 (str vs dt 비교!)
구분str 메서드 (문자열)dt 메서드 (날짜)
| 사용 대상 | 문자열 (object) | 날짜 (datetime64) |
| 기능 | 텍스트 처리 (소문자 변환, 패턴 추출, 공백 제거 등) | 날짜 정보 추출 (연, 월, 일, 요일 등) |
| 대표 메서드 | str.lower(), str.split(), str.contains() | dt.year, dt.month, dt.weekday |
| 예제 | data['Name'].str.upper() | data['Date'].dt.year |
✔ str → 문자(string) 처리! (소문자 변환, 특정 단어 찾기)
✔ dt → 날짜(datetime) 처리! (연, 월, 일, 요일 추출)
'데이터 분석가:Applied Data Analytics > 판다스 데이터분석' 카테고리의 다른 글
| 4. Data transformation - 영국시장의 중고 자동차 가격 데이터 다루기[프로젝트] (0) | 2025.02.13 |
|---|---|
| 3. Data transformation (0) | 2025.02.12 |
| 6장_데이터프레임의 다양한 응용(데이터프레임 합치기) (0) | 2025.02.10 |
| 6장_데이터프레임의 다양한 응용 (0) | 2025.02.10 |
| Matplotlib (1) | 2025.02.07 |