320x100
728x90
1. 혼동행렬(Confusion Matrix)의 개념
혼동행렬은 분류 모델이 얼마나 잘 예측했는지 확인하는 표 형태의 도구입니다.
분류 결과를 실제값과 예측값에 따라 네 가지로 구분하여 표현합니다.
| 구분 | 예측 Positive (P) | 예측 Negative (N) |
| 실제 Positive (P) | TP (True Positive, 진짜 양성) | FN (False Negative, 가짜 음성) |
| 실제 Negative (N) | FP (False Positive, 가짜 양성) | TN (True Negative, 진짜 음성) |
- TP: 실제로도 양성, 예측도 양성 (정답)
- TN: 실제로도 음성, 예측도 음성 (정답)
- FP: 실제로는 음성이나, 양성으로 잘못 예측한 경우 (오류)
- FN: 실제로는 양성이나, 음성으로 잘못 예측한 경우 (오류)
2. 평가 지표의 개념과 공식
(1) 정확도(Accuracy)
전체 예측 중 정확하게 맞춘 비율입니다.
즉, "모델이 전체 예측 중 얼마나 많이 맞췄는가?"를 나타냅니다.
- 정확도의 공식
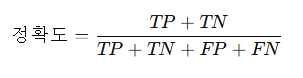
- 특징
- 데이터의 클래스가 균형 잡혀있을 때 유용합니다.
- 클래스 불균형 상황(예: 희귀질환 예측)에서는 잘못된 판단을 내릴 수 있습니다.
(2) 정밀도(Precision)
양성이라고 예측한 결과 중 실제로 양성이 맞는 비율입니다.
즉, "양성으로 예측한 것 중 얼마나 실제로 양성인가?"를 나타냅니다.
- 정밀도의 공식

- 특징
- FP(가짜 양성, 오탐)를 줄이는 것이 중요할 때 사용합니다.
- "스팸 메일 분류, 암 진단"과 같이 오탐이 문제를 일으킬 경우 중요합니다.
(3) 재현도(Recall, 민감도, Sensitivity)
실제 양성 중 모델이 얼마나 많이 양성으로 찾아냈는지 나타내는 비율입니다.
즉, "실제 양성 데이터를 얼마나 놓치지 않고 찾아냈는가?"를 나타냅니다.
- 재현도의 공식
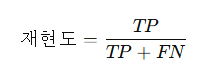
- 특징
- FN(가짜 음성, 놓친 양성)을 줄이는 것이 중요할 때 사용합니다.
- "질병 진단, 사기 탐지"와 같이 놓쳤을 때 큰 위험이 따르는 분야에서 중요합니다.
3. 요약 및 정리
| 평가 지표 | 핵심 의미 | 공식 |
| 정확도(Accuracy) | 전체 중 얼마나 정확히 맞췄나? | (TP + TN) / (TP + TN + FP + FN) |
| 정밀도(Precision) | 양성이라 예측한 것 중 얼마나 진짜 양성인가? | TP / (TP + FP) |
| 재현도(Recall) | 실제 양성 중 얼마나 놓치지 않고 찾아냈나? | TP / (TP + FN) |
4. 추가 팁
- 정확도는 클래스가 불균형한 데이터에서는 신뢰하기 어렵습니다.
- 정밀도와 재현도는 서로 Trade-off 관계이며, 상황에 따라 우선순위를 결정하여 사용합니다.
'데이터 분석가:Applied Data Analytics' 카테고리의 다른 글
| 선형대수학(Linear Algebra) 개요 (0) | 2025.03.10 |
|---|---|
| 빅데이터분석기사 25일 시험공부 계획 (0) | 2025.03.09 |
| 머신러닝 이해하기(분류) (1) | 2025.03.07 |
| 캔바(Canva)란? (0) | 2025.03.06 |
| 데이터 기반 의사결정을 위한 확률 및 분포 5-2] (0) | 2025.03.06 |