주정민 강사님 : 통계학과 재학이후 데이터분석가 로 현직에서 경험이 많으신 강사님
라피레터,
확률과 분포도 전통적인 분야라 책으로도 추천한다.
모든 토글을 열고 닫는 단축키
Windows :Ctrl + alt + t
Mac : ⌘ + ⌥ + t
1. 확률과 통계를 어떻게 쓰나
데이터를 잘쓰는 회사별로 있다 (예: 쿠팡 정도가 최상)
초기 스타트업은 : 데이터엔지니어가 더 필요하다.
데이터가 많은 회사를 추천한다. 공고에 JD를 세부적으로 봐서 참고해야
설명적 분석 : 루틴한 작업, 진
진단적 분석 : 셀프 서비스 분석, 시각화, A/B 데트스 도입(사내 구축이 되어있다)
기술블로그 추천함
예측적분석 : 머신러닝, 지금은 데이터분석가(데이터분석하고 모델링하는)는 머신러닝은 많이 하지 않는다
와 데이터사이언티스트는 분리되는 경향.
처방적 분석 : 다이나닝플러싱(머신러닝도 배워야된다), 최적화, ML/DL
보통 회사에서는 클라우드환경에서 하던지 요즘은 데이터웨어하우스 구축된곳이 많다
2. Ad-hoc분석(엑셀 시트 레포트, 시각화, 단순한 지표추출, 기술 통계량) 챗gpt로 자동화 되긴 한다
지표와 시각화(Looker, Tableau 등)
파이썬, SQL(60%), Tableau도 많이씀 해보는게 중요,
Tableau란?
 Tableau를 배우는 방법
|
Ad-hoc 분석이란?
- 정의
- Ad-hoc 분석은 특정한 문제를 해결하거나 즉각적인 의사 결정을 위해 임시로 수행하는 데이터 분석을 의미한다.
- 사전에 정해진 보고서나 대시보드가 아니라, 필요할 때마다 즉각적으로 실행되는 분석 방식이다.
- 특징
- 비정형적(Non-routine) 분석: 정해진 포맷 없이 문제에 따라 유연하게 수행된다.
- 빠른 의사결정 지원: 즉각적인 질문에 대한 답을 얻기 위한 분석으로, 빠른 결론을 내리는 데 도움을 준다.
- 일회성 분석: 동일한 분석이 반복적으로 수행되지는 않으며, 특정 목적을 위한 분석에 초점이 맞춰진다.
- 도구 활용의 유연성: SQL, Python, Excel, BI 도구(Tableau, Power BI) 등 다양한 도구를 활용할 수 있다.
- 예제
- 마케팅 팀: 특정 프로모션이 매출에 미친 영향을 즉각적으로 분석
- 고객 지원 팀: 특정 기간 동안 고객 불만 증가 원인 파악
- 제품 팀: 특정 기능이 사용자 참여율에 미치는 영향 분석
- Ad-hoc 분석과 정기 보고서의 차이
비교 항목 / Ad-hoc 분석 / 정기 보고서목적 특정 문제 해결, 즉시 대응 일정 주기별 정기적인 보고 실행 방식 필요할 때마다 수행 미리 정의된 데이터와 포맷 사용 데이터 활용 실시간/최신 데이터 활용 고정된 데이터 범위 사용 예제 특정 이벤트의 효과 분석 월별 매출 보고서 - Ad-hoc 분석의 장점과 단점
장점- 문제 발생 시 즉각적인 인사이트 제공
- 유연한 접근 방식으로 다양한 문제 해결 가능
- 고정된 보고서가 제공하지 않는 심층 분석 가능
- 분석에 시간이 걸릴 수 있음 (특히 데이터 정리가 필요할 경우)
- 동일한 분석을 반복적으로 수행할 경우 비효율적
- 비정형적 분석이기 때문에 일관성이 부족할 수 있음
- 활용 사례
- 기업 경영: 특정 분기의 매출 하락 원인 분석
- 의료 데이터 분석: 특정 질병 발생률 증가 원인 탐색
- 소셜 미디어 분석: 특정 캠페인 이후 사용자 반응 즉각 분석
Ad-hoc 분석은 유연하고 즉각적인 문제 해결을 위한 중요한 분석 방법으로, 데이터 기반 의사 결정을 지원하는 데 필수적인 역할을 한다.
3. Daily Scrum 이란?
- 정의
- Daily Scrum은 Scrum 프레임워크에서 개발 팀이 매일 짧은 시간(일반적으로 15분) 동안 진행하는 미팅이다.
- 팀원들이 현재 진행 상황을 공유하고, 장애물(문제점)을 확인하며, 목표를 조정하는 것이 목적이다.
- 목적
- 팀원 간의 투명한 소통을 강화하고, 작업의 진행 상황을 공유한다.
- 프로젝트의 진행 상태를 점검하고, 목표 달성을 위한 조정을 한다.
- 문제가 있다면 빠르게 해결책을 찾을 수 있도록 한다.
- 협업을 촉진하고, 팀이 하나의 목표를 향해 정렬될 수 있도록 한다.
- 진행 방식
- 일반적으로 하루의 시작(업무 시작 전)에 진행되며, 15분 이내로 마치는 것이 원칙이다.
- 팀원들이 각자 다음 세 가지 질문에 대해 간략히 답변한다.
- 어제 무엇을 했는가?
- 오늘 무엇을 할 계획인가?
- 진행에 방해되는 장애물이 있는가?
- 스크럼 마스터(Scrum Master)는 진행을 지원하지만, Daily Scrum을 주도하지 않는다. 팀원들이 자율적으로 진행한다.
- Best Practice
- 정해진 시간과 장소에서 매일 같은 방식으로 진행하여 습관화한다.
- 15분 내로 짧고 집중적으로 진행한다.
- 문제 해결은 별도 미팅(After Meeting)에서 다루고, Daily Scrum에서는 공유 중심으로 진행한다.
- 전체 팀이 함께 참여해야 하며, 서서 진행하면 시간을 단축할 수 있다.
- 일반적인 오해
- Daily Scrum은 상태 보고(Status Report) 미팅이 아니다.
→ 상사에게 보고하는 자리가 아니라, 팀원 간 협업을 위한 자리다. - 스크럼 마스터가 주도하는 미팅이 아니다.
→ 팀원들이 자율적으로 진행해야 한다. - 문제 해결을 위한 회의가 아니다.
→ 문제가 나오면 공유만 하고, 해결은 별도 회의에서 진행한다.
- Daily Scrum은 상태 보고(Status Report) 미팅이 아니다.
- 유사 개념과 비교
- Stand-up Meeting
- Daily Scrum과 유사하지만, Scrum을 사용하지 않는 팀도 활용할 수 있는 일반적인 일일 회의다.
- 형식이 비교적 자유롭고, Scrum의 원칙을 따를 필요는 없다.
- Status Meeting
- 관리자가 팀원의 진행 상황을 체크하는 보고 회의로, Daily Scrum과 다르게 일방적인 보고 형식이 될 수 있다.
- Stand-up Meeting
Daily Scrum은 효율적인 협업과 투명한 소통을 위한 핵심 Scrum 이벤트로, 잘 활용하면 팀의 생산성을 높이고 프로젝트 목표를 달성하는 데 큰 도움이 된다.
엑셀에서 하던걸 자동화 한다. Overview대시보드, By Dimension 대시보드,
4. 데이터 분석 프로젝트
A/B테스트
5. 데이터기반 의사결정
Data-Driven보다 Data informed 을 적용하는 추세다.
데이터를보고 데이터외에 다른 부분을 정량적 과 정성적인( 외부적인요인 다른검색으로 원인을 찾아보는) 부분을 같이 파악필요.
경쟁사와 비교도 필요하다(항상 기준을 어디에 두느냐가 중요. 기준에 따라 평가가 달라지기 때문)
기준에 대한 평가는 데이터를 많이 분석해 봐라.
기준을 잡아놓고 기준을 뜯어보기를 추천
항상 정량, 정석 으로 해봐야 한다.
다양한 데이터를 보는게 좋다.
포트폴리오에는 3개정도 중요한 프로젝트를 넣는게 좋다.
확률이란 무엇일까?
확률 = 사전이 일어날 경우/전체경우의 수
A/B테스트할때 통계를 봐야한다.
기술면접 스크립트 해두면 좋다(노션에 기록해두면 좋다)
DA에는 기술면접때 쿼리 많이 물어본다.
확률의 공리란? P(A)
표본 공간(Sample Space) S
표본에 대한 확인이 필요하다.(비율적으로 봐라 비율지표가 중요하다)
VA분석이 중요하다
모집단
웹사이트 A/B 테스트 에 대한 보고서, AARRR 등
빈도주의적 확률 관측된 데이터로 기준 (많이 씀)
빈도주의적 확률(Frequentist Probability) 개념 정리1. 빈도주의적 확률이란?빈도주의(Frequentist) 확률은 어떤 사건이 무한히 반복되는 실험에서 얼마나 자주 발생하는지를 비율로 정의하는 접근 방식이다. 즉, 실제 시행을 통해 경험적으로 확률을 측정하는 방법이다.2. 빈도주의 확률의 정의어떤 사건 AA가 총 NN번의 실험 중에서 nn번 발생했다면, 그 사건의 확률 P(A)P(A)는 다음과 같이 정의된다.P(A)=limN→∞nNP(A) = \lim_{N \to \infty} \frac{n}{N}즉, 실험 횟수 NN이 무한히 커질 때, 사건 AA가 발생하는 비율이 사건의 확률이 된다. 이를 통해 확률이 장기적인 평균적 비율로 해석된다. 빈도주의 확률의 핵심 특징
빈도주의 확률의 예시1. 동전 던지기 실험
2. 주사위 던지기
빈도주의 확률의 한계점
|
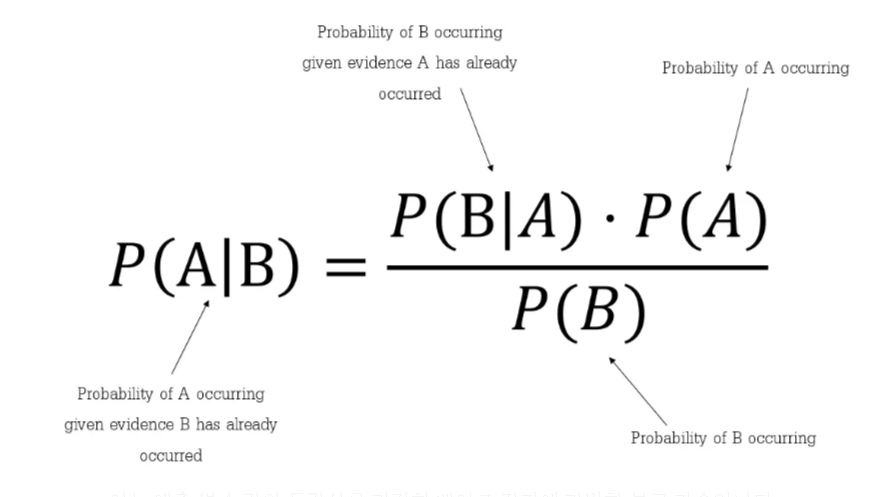
베이지안 확률(어떤 사건에 주간적인 믿음이 영향) 빈도주의 + 사전지식
정확도의 면에서는 반영을 계속하기때문에 조금은
베이지안 확률은 불확실성을 다루는 수학적 접근법으로, 새로운 증거가 등장했을 때 기존 믿음을 업데이트하는 방법을 제공합니다. 이 개념은 18세기 영국의 수학자 토마스 베이즈에서 유래했습니다.베이지안 확률의 기본 개념베이지안 확률은 확률을 '믿음의 정도'로 해석합니다. 이는 전통적인 빈도주의 확률(사건의 발생 빈도)과 대비됩니다. 베이지안 접근법에서는 사전 지식이나 믿음을 가지고 시작하여, 새로운 데이터가 들어오면 이를 업데이트합니다.베이즈 정리 (Bayes' Theorem)
|


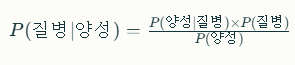

간단 문제
1) 주사위 던졌을때 짝수가 나올확률은? 1/2
2) 동전을 두번 던졌을때, 적어도 한번 앞면이 나올확률은? 3/4
3) 한 웹사이트의 방문자중 20%가 구매한다고 가정할때, 랜덤하게 선택한 3명의 방문자가 모두 구매할확률은?
0.2*0.2*0.2=0.008(0.8%)
4)A/B테스트에서 그룹A 전환율이 5% 그룹B는 7%라면 그룹B에서 전환이 일어날 확률이 더 높다는것을 확률적으로 설명할때 는(표본크기와 통계적검정 제외) 베이지안으로 푼
a,b 각각 0.5씩 가져감. a에속할 확률 = b에 속할 확률 = 50%
전환 발생 확률 = 0.5*0.05+0.5*0.07 = 0.06
전환 a 에서 발생할 확률 = 0.5*0.05/0.06 = 41%
전환 b에서 발생할 확률 = 0.5*0.07/0.06 = 58%
b 가 높음
2%p(포인트 끼리의 비교는 뒤에 p를 붙여야된다)
데이터로 가치를 만드는 Steven, Follow on LinkedIn
'데이터 분석가:Applied Data Analytics' 카테고리의 다른 글
| 데이터 분석가 커리어관리 추천 툴 (1) | 2025.03.01 |
|---|---|
| 확률과 분포 이해하기 2] (0) | 2025.02.28 |
| '제 자리'를 찾는 Career Repotting Project (0) | 2025.02.28 |
| 플랜트 일정 데이터(XER 파일) 기반 일정 예측 모델 구축 (0) | 2025.02.28 |
| 공정관리 와 데이터 과학자 레벨업 (0) | 2025.02.28 |